6 minutes read
This article covers an older version of the source code linked below. A few additional options, like filtering
spam-tweets, came in but the base functionality remained the same. If you experience any problems using the
newer versions, please, leave a comment.
I am a Twitter-Addict. Most of my coding-related stuff comes from links and suggestions via Twitter. And of course I’m using it everywhere, from desktop to smartphone, while travelling, or at work. My carefully defined feeds are always fresh & flowing. However, sometimes I just want to have all the interesting tweets collected in one place without any external complexities, whistles & bells.
It should be configurable via JSON and I want to collect the incoming data for later processing because these days no data is useless.
Well, what about an easily configurable, console-based Twitter Client with colorized output that can persist tweets to a database?
In this article we’ll develop such a client with Python v.2.7
Accessing the Twitter API
Probably most of you already know that Twitter expects an app to have a number of keys generated before it can connect their API. The creation and management of these keys is done via Application Management. To create a new app click on the button Create New App and fill in the details:
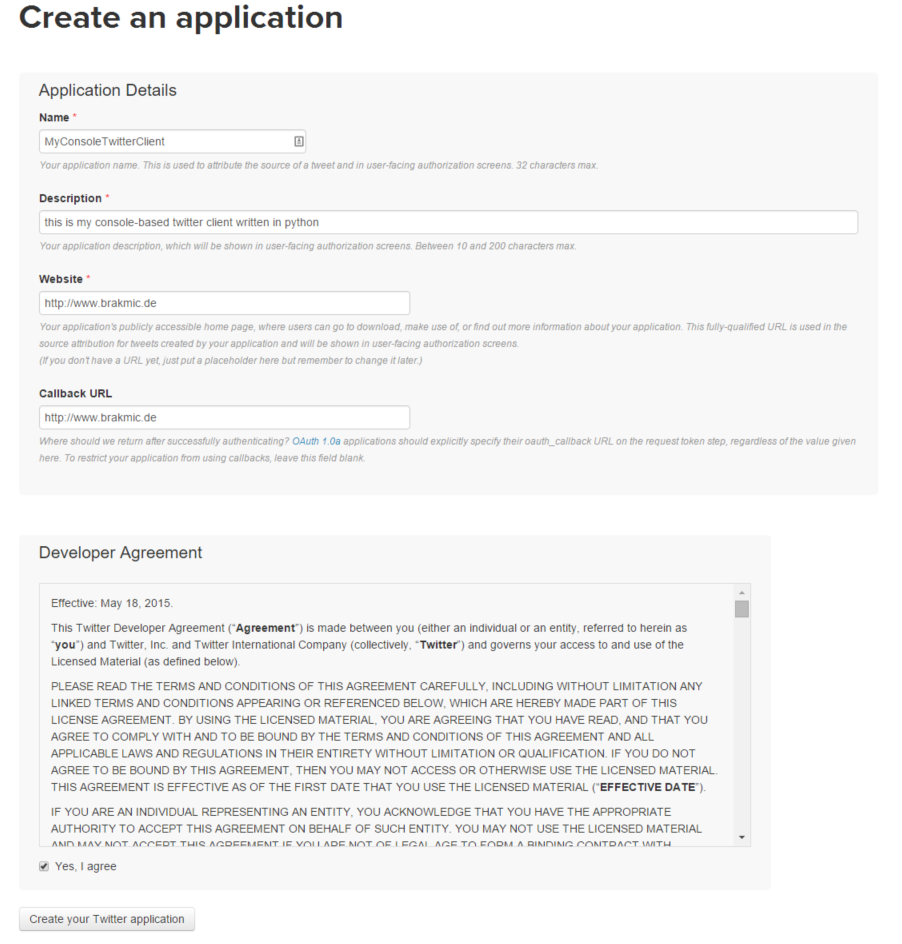
After clicking on Create your Twitter application you should see a window like this.
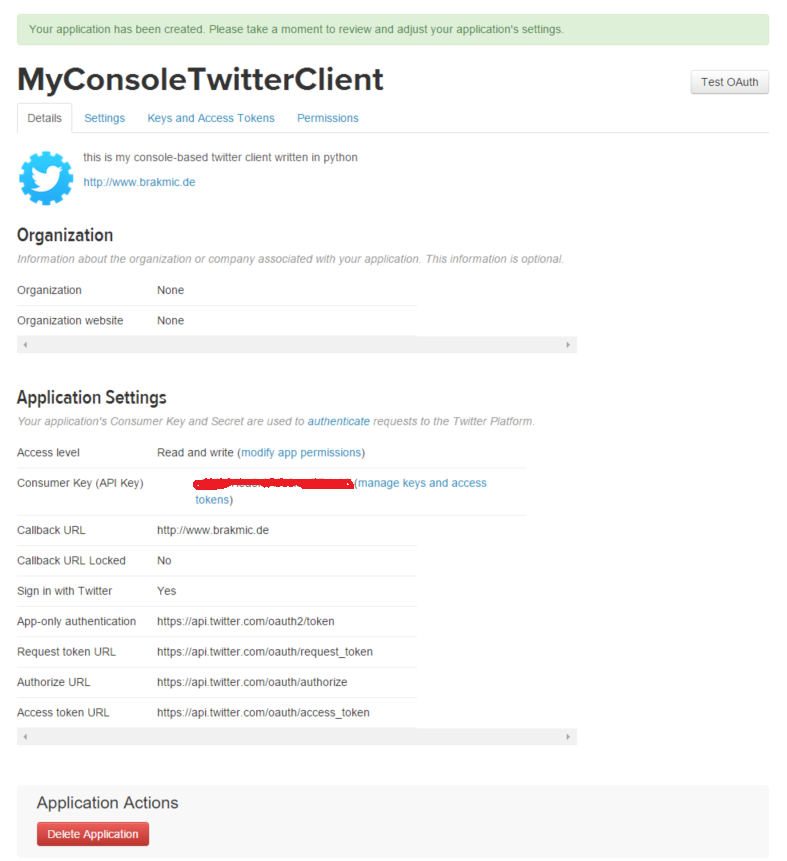
The important parts are the Consumer Key (API Key) and the Keys and Access tokens in the third tab. These you’ll use to create a JSON config file for this application.
Communicating with Twitter API
OAuth is pervert. Period! I never liked it. Of course, it does all the nice things and doing nothing regarding communication security is outright stupid but in this case all we want is a simple Twitter Client. Therefore we’ll use the Tweepy Library to properly connect with the Twitter API. The installation is easy and depends on your preference: pip, manual install etc. From tweepy we’ll import Stream, OAuthHandler and StreamListener. To setup a connection we have to instantiate an OAuthHandler with our Consumer Key and Consumer Secret (from the third tab in the application configuration). Then we set the Access Key and Access Token by invoking a certain method from the same OAuthHandler instance.
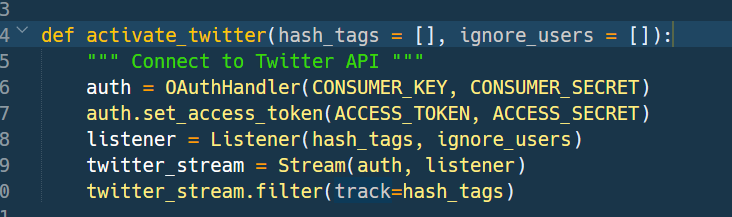
Now we need a proper implementation of the StreamListener from Tweepy. This object must implement a set of methods which will be called by the Stream instance when new tweets arrive. In this article we’ll implement only two of them: on_data and on_error. But there are many more available.
And finally our Stream instance will only track tweet-streams which contain certain terms (hash_tags).
Implementing a Listener
Tweepy Stream class expects an object that implements a certain set of methods. Our Listener implementation defines on_data (for new tweets) and on_error (when something goes wrong). Additionally, we can persist incoming tweets to a database. This, of course, could have been done separately in some other class or via event handlers but I didn’t want to create an overly complex twitter client. I know, I know, it is way better to separate concerns and creating God objects isn’t a very good idea. Feel free to refactor it, or simply laugh at me and let Twitter know how bad I’m at software engineering. 😳
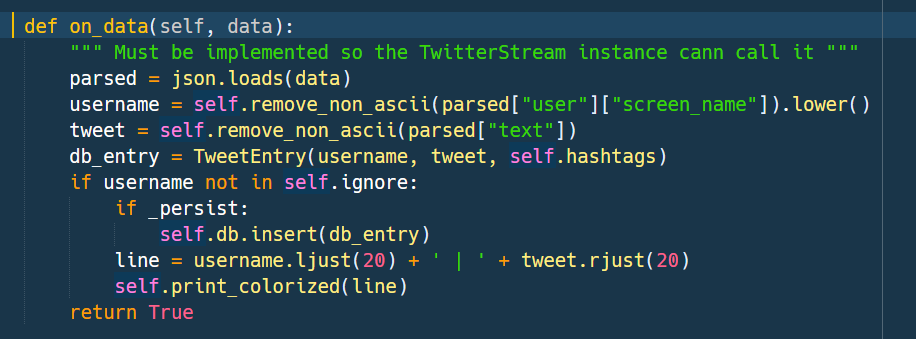
In on_data method we load the tweets as JSON strings and extract their text and user data. payloads. Subsequently we create a simple transportation object TweetEntry. Tweets belonging to blocked users are being ignored and neither show up in the console nor get persisted. Saving to a DB is done via checking the _persist flag for True.
Persisting Tweets
Here I’m using MS SQL to save my tweets but any other ODBC-capable database would do it. Just create a proper DSN entry and let the PyODBC library know about it.
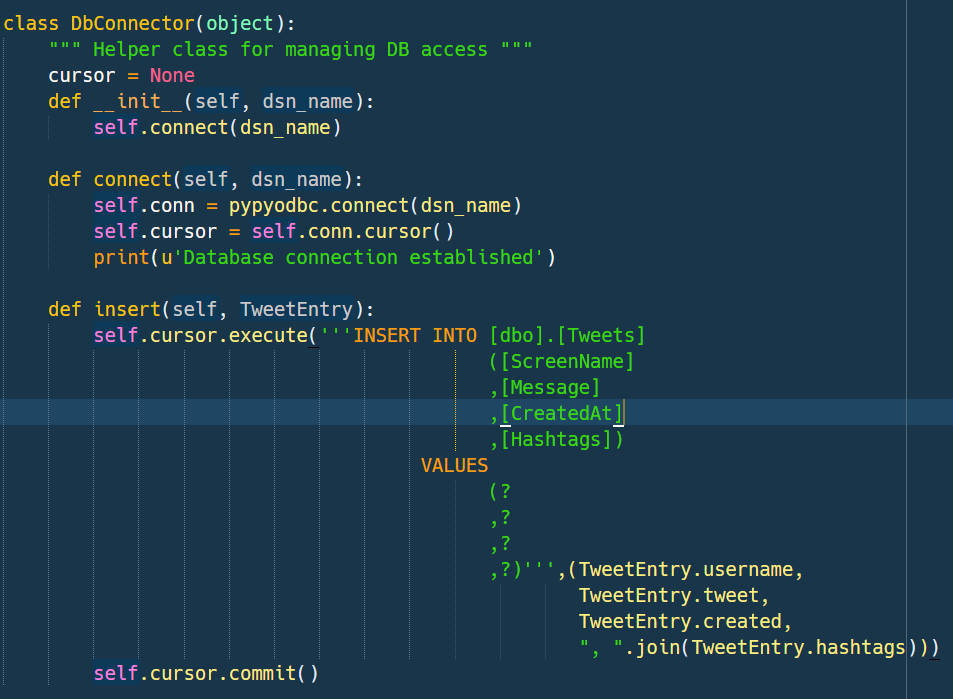
The table where the tweets will land contains five fields: Id, ScreenName, Message, CreatedAt and Hashtags.
This is the CREATE script for MSSQL:
CREATE TABLE [dbo].[Tweets]( [Id] [bigint] IDENTITY(1,1) NOT NULL, [ScreenName] [nvarchar](50) NULL, [Message] [nvarchar](500) NULL, [CreatedAt] [datetime2](7) NULL, [Hashtags] [nvarchar](max) NULL, CONSTRAINT [PK_Tweets] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
The method insert of DbConnector is used inside the method on_data in the Listener instance to persist incoming tweets.
Colorizing the Output
Writing large amounts of data to the console can quickly become a very messy “reading experience”. To raise the recognition level for a bit I’ve used the nice Colorama library to colorize certain parts of incoming tweets. The result looks like this:
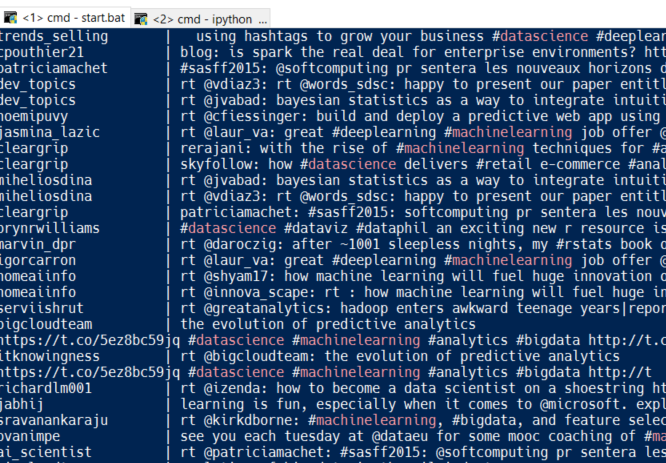
Here I’m colorizing my preferred hashtags.
The whole logic is located in a single method print_colorized:
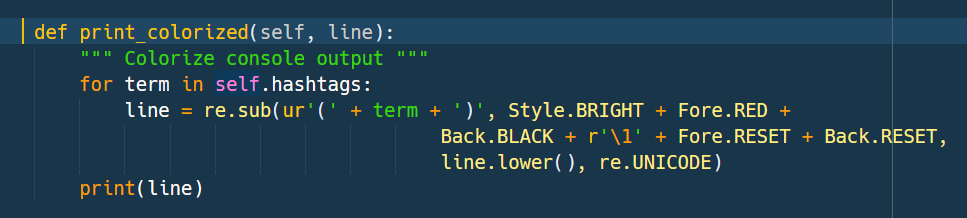
I’m using a simple regex to locate the term inside the tweet and set the color commands before and after it. Basically, it works like a simple switch.
Configuration via JSON
The original version of this client offered a bunch of console parameters but this proved to be too rigid and not very scalable. Therefore I switched to JSON which can now be easily expanded according to any changes in the app. The JSON configuration file comprises of following parts:
- Main config object
- services with db and twitter entries
- ignore array
- filter array
All config settings must be located inside the config object. The Twitter-API Keys and Tokens are in services.twitter. If database is used then its DSN settings must be put in the connectionstring entry. To disable writing to db just set active to false. To avoid twitter spam put its “screen name” in the ignore array. The screen names look like those in the screenshot above. Just copy/paste the spammer’s name to let him jump into /dev/null. If you want only to receive tweets containing certain terms then expand the filter array with your preferred entries.
Starting the Client
Just type in python twitter_client.py –config=YOUR_CONFIG_FILE and soon the tweets will flow into your console.
Have fun!


{kind=link}
{kind=link}
{kind=link}
3 thoughts on “Writing a Console Twitter Client in Python”
I couldn’t run the code
Did you change something anywhere in new code ?
python TwitterClient.py –config=[config.json] doesn’t work for me!!!
What’s the error message?
i am trying to like tweets by standard tweepy api problem i am facing is that like tweets don’t have any kind of sequence e.g i want to like 10 tweets by using cursor [‘tweepy.Cursor(api.search, q=keywords, lang=”en”, result_type=’recent’).items(count )’] it will like 10 tweets but when i see these tweets on twitter search its liking sequence can not be understandable .Any help would be highly appreciateable