
10 minutes read
- Intro to Semantic Kernel – Part One
- Intro to Semantic Kernel – Part Two
- Intro to Semantic Kernel – Part Three
- Intro to Semantic Kernel – Part Four
- Intro to Semantic Kernel – Part Five
- Intro to Semantic Kernel – Addendum
In this article, we will learn how to use Planners with Semantic Kernel. As we have seen in the first article, the SK is capable of utilizing semantic and native functions that are used in collections called Plugins (previously named “Skills”). With semantic functions, we write a prompt template in plain text and let SK send it against an LLM. Native functions on the other hand offer us the advantage of reusing our programming skills to define functions in C#, Python, or Java that SK can use together with semantic ones. There is, in fact, no difference between the two types of functions. SK deals with them the same way. However, using either function types by programmer’s command is nothing exceptional as programming is exactly that: telling a machine what to do when this or that happens. AI is supposed to be “intelligent” and one of the traits of intelligence is the capability to decide autonomously what to do in certain circumstances. So, how can we make our SK-applications behave in a more intelligent way? Enter Planners. 🙂
What are Planners?
By definition, a Planner is a mechanism to autonomously orchestrate AI tasks based on a user’s request. In SK, there exist multiple variants of Planners that belong to so-called “generations”. These are:
- Basic Planner (available for the Python variant of SK only, a basic JSON-based Planner )
- Action Planner (1st gen.)
- Sequential Planner (2nd gen.)
- Stepwise Planner (3rd gen.)
The Basic Planner is only available for Python and is capable of creating JSON-formatted plans. As this article series is focused on .NET, I won’t be using much Python here, but if you are interested in Basic Planner for Python, check out this code.
The Stepwise Planner won’t be covered in this article, but let me describe it at least:
- The Stepwise Planner runs on a neuro-symbolic architecture known as MKRL (pronounced “miracle”), which stands for Modular Reasoning, Knowledge and Language. It’s particularly suited for scenarios requiring dynamic plugin selection and handling complex asks with interconnected steps. The planner can learn from its mistakes during the exploration of functions or plugins to solve problems.
The Action Planner is a very simple Planner that is capable of selecting one function to fulfill a task. Imagine, you created a task that should do some HTTP queries. Luckily, you already have an HttpPlugin that can execute the usual GET, POST, and PUT requests.
Now, depending on the task description you gave to SK, the Action Planner would then select the appropriate native function to execute a request. Here is how we use the Action Planner to download an HTML document.
An Action Planner, therefore, behaves almost like an if-then statement. And it has no “else“, because there is no alternative to the single Plugin function it can select. Either it finds a suitable one or it fails with an error message explaining all the steps it took while trying to find a solution.
The source code repository of this article contains descriptions that can be used with Planners from this article.

If you are using VSCode, there are a few launch configurations available. Try them out and watch the Planner’s behavior.

But before you execute any of those, make sure you have activated the compatible Run* function in the Program.cs. I wanted to avoid maintaining multiple source files, so I do it via command handler, which also makes it possible to pass function name parameters (only needed when executing functions described in the previous article).

Why do we need Planners?
But you might now ask, why do I need such a Planner when I can write if-then-else myself, or more complex statements? What’s the point of all this “artificial intelligence” stuff when in the end it still does the same old, boring “if-then-else”? Well, the difference lies in the scale and complexity it entails, I would argue. Small problems demand small solutions. And solutions of scale are usually more complex than a bunch of if-then-elses, isn’t it?
Imagine a company with hundreds or even thousands of APIs, spread over various teams, with documentation that differs in size, precision, and quality. How do you make sure that the “correct” API can be discovered and used the right way, with valid arguments, and the data returned can be parsed just as correctly? Various solutions to such problems of scale have existed for decades, defining Service Providers, Discovery Protocols, Registries and so on. However, the problem lies in the propagation of ever-changing information. As soon as one tiny little part of a bigger system changes its description or implementation, it must make sure other parts have noticed this change. In a small-scale system, this is not a big deal, even if one team member fails to inform the colleagues. The immediate error shown in the IDE is very often a good clue where a fix needs to be implemented. Not so in systems of scale with different teams, responsibilities, access rights etc. Therefore, we need a solution that can adapt to change, heal itself autonomously, rethink previous solutions, and come up with new ones (including those not imagined at the initial design). And just like systems can change, our expectations of them change as well. What if someone asks a system to do something novel, never heard of before? In a traditionally programmed system, the result will be either invalid data or an outright error message. But do we want “intelligent” systems to behave like spoiled children? Or incompetent bureaucrats, unwilling to adapt to even the slightest change in requirements? This is also where systems powered with Semantic Kernel and similar libraries really shine. Because they not merely execute some parts of predetermined code, but creatively react to our inputs. Non-determined systems are a much better fit to our anything but deterministic world.
Semantic Similarities and Semantic Completion
Before we dive into Sequential Planners, which are the real deal and can show us how powerful Semantic Kernel is, I would like to mention a few things from “theory” just to put everything into perspective.
When we use tools like ChatGPT, we deal with Semantic Completions, a group of stochastic methods (that is: we’re dealing with probabilities) that try to estimate the next best completion of the prompt we just sent. This is also the reason why “Prompt Engineering” has become so important these days. It’s the Prompt that drives the LLM. The better the prompt, the greater the probability LLM will find a correct completion (from our human point of view). This is also why the maintenance of extremely multi-dimensional LLM data is so important and no wonder there are scientific texts on how “ChatGPT is getting dumber“. It’s of course not getting dumber in a psychological sense, but it’s simply returning completions of lower quality over time.
But Semantic Completion alone is not enough to express the real nature of SK. We need the other half of the equation to get things done: Semantic Similarity. This half deals with selecting the most promising step that is needed to fulfill a particular task. A prompt asking for a description of a movie can be completed directly by ChatGPT and similar tools. But what about a prompt asking to do multiple and very different tasks, maybe running in different dimensions outside of the prompt, but still depending on each other? Like this one describing a DevOps task:
Try this out in ChatGPT. It won’t work as you might expect.

For example, ChatGPT cannot generate TLS certificates, or encode them in base64. At least, I wouldn’t trust any LLM to do this for me. Also: would you really want to let ChatGPT know anything about your TLS-certificates, even self-signed ones? And why this extra “Do not use Helm” line? Would ChatGPT try to run Helm for us, for free? No, of course not. This has something to do with Sequential Planner and how it manages Plugins. We’ll see that in the examples below. And I hope, you understand now, why Semantic Completion is only the first half of a bigger whole. Let’s now learn about the second one, Semantic Similarity, as this is what makes Sequential Planners useful.
Sequential Planner
The Sequential Planner is a component of SK designed to streamline the execution of a series of steps, transferring outputs from one stage to the next as warranted. This is particularly advantageous in scenarios necessitating the sequencing of plugins together. The previously shown task on creating Kubernetes Secret YAML and their base64-encoded key and cert fields is one such example. Also, the last line that prevents the use of a potential alternative, the Helm package manager, is an example of how we can instruct the Semantic Planner to ignore certain potential functions while trying to figure out the solution that fulfills the given task.
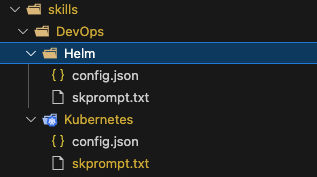
Just like with the Action Planner, we simply load all available functions from Plugins, be they semantic or native ones. Then we read the instructions from the file and let the Sequential Planner devise a plan. To see the plan in the console, we can use this method from the Sequential Planner:
plan.ToSafePlanString()
The Sequential Planner was able to select three functions from two different Plugins:
- KeyAndCertGenerator: GenerateBase64KeyAndCert and Extract
- SecretYamlUpdater: UpdateKubernetesSecretYamlString
You can trace the execution flow by putting breakpoints into the respective functions. Also, the second function, Extract, will be called two times, because the two fields in the Secret YAML (cert, key) contain different values and the Sequential Planner correctly recognized that. So, we will get two base64-encoded strings, one for “cert” and the other for “key”. This is the result of the execution, a valid Kubernetes Secret YAML that we now can use with “kubectl apply -f secret.yaml”

As already mentioned, the Sequential Planner uses any fitting function, be it a semantic or native one. Here is an example where it executes a more complex DevOps task that involves the deployment of Keycloak, NGINX-Ingress, their Services, and it also generates the needed Certificates to be used in Ingress for HTTPS communication.

There are innumerable ways of using the Sequential Planner and I have only shown really simple examples that also could be made manually or with simple shell scripts. But sooner or later the scaling problems kick in, accompanied by lack of precise knowledge, inconsistent information, and human proclivity to forget things. In such cases, a Planner that is capable of finding Similarities between what should be done and how it could be done is the missing “other half” in our world that is still learning how to use the glorified Text Completion Engines like ChatGPT.




{kind=link}
{kind=link}
{kind=link}
{kind=link}