
10 minutes read
Yesterday, I discovered an experimental Big Data processing framework written in C++ called Thrill. As most of you surely know, the well-known frameworks of this kind are mostly based on JVM, like Apache Spark or Apache Flink. This, of course, has many advantages, like easily accessible interfaces and a more domain-oriented approach, as we don’t have to deal with “Ceremony Code” or any internals that don’t touch our domain logic. However, everything comes at a cost and utilizing a VM is a price to be paid no matter how optimized your code is. It’s no wonder these projects often resort to Unsafe and similar tricks to keep the JVM GC away from their precious resources. Anyway, this article’s intention isn’t to attack these projects or JVM but simply to show a fast yet easily usable framework that runs on native code. Although the project’s source code is portable and can compile under Windows (I tested it) some important interfaces, like networking, are currently only available as mocks. Therefore, for any more serious application I’d recommend using a Linux box or WSL (Windows Subsystem for Linux). I this article I’ll show you how to compile Thrill and a small test app by using WSL.
The source code is located here.
What is Thrill?
By its own definition Thrill is a framework for distributed batch computations of massive data a.k.a “Big Data”. It’s an university project from Karlsruhe Institute of Technology and a very detailed presentation containing example code can be found here. For C++ enthusiasts among you one very important aspect would be the fact that Thrill utilizes much of the modern C++ features like lambdas and automatic type deduction. And of course, template meta-programming isn’t far away and in fact, Thrill relies heavily on it. The source code is available on GitHub. Although I’m not very experienced in Thrill there are a few things one should take into account before trying to build the framework and/or apps that utilize it. And I hope this article will help others save their time while building the environment.
Preparing the Environment
I’m using Windows 10 that runs an Ubuntu-based Linux Subsystem. If you don’t know how to activate it, visit this article before going any further.
Now in the opened Bash console install these tools and libraries:
sudo apt-get install git cmake autoconf libtbb-dev libhdf3-dev libbz2-dev zlib1g-dev libxml2-dev libcurl4-openssl-dev libboost-all-dev
Thrill needs a C++ compiler that understands the new standard so the default one, g++ 4.8, won’t be sufficient. Execute these few lines of code to make your Ubuntu know about an alternative location where it can find the 5.x version of g++.
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install gcc-5 g++-5
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 60 --slave /usr/bin/g++ g++ /usr/bin/g++-5
Now type in g++ –version to check if you’re running a 5.x version. The output should be similar to this one:

Given that you now have a more modern G++ we can proceed with checkout of the latest sources from Thrill repository.
git clone https://github.com/thrill/thrill.git
Go into the new directory and execute compile.sh script.
./compile.sh
If the script doesn’t start, please, check if the execution bit is set. If this isn’t the case type:
chmod +x compile.sh
Then try to execute the script one more time. When everything goes well you’ll see an output like this. Please, be patient as the building process involves several other GitHub repositories and execution of tests.

Of course, a framework alone isn’t sufficient enough. Soon we’ll want to run our own logic that utilizes the primitives offered by the framework (functions like Map, FlatMap, Reduce etc.). That’s why I’ve created the small demo repository linked at the beginning of the article. There you’ll find the same source code but this time embedded as an extlib (external library) that’ll be checked out by the compile.sh script and linked with your code each time you start a new build. So, if you have some code that should run on Thrill just put it into the repo and write the to-be-compiled sources in the CMakeList.txt.
We’re using CMake here because we support different OS-es. But before we start to build the demo app let’s talk about Thrill.
Everything is Immutable – Everything is Functional
Thrill doesn’t like mutable data and this is for a reason. Because it can run on different machines there should be no room for changing data that flows between different them. If some machine (or “worker”) relies on certain values it’d be very problematic if some other worker could simply change this data. Therefore, everything in Thrill is immutable. This approach is, of course, very “functional” and those of you who know Haskell would say that I’m not talking about anything new or exciting. This is “old school”, yes, I know. However, immutable data by itself is not of much use, just as forbidding any side effects in code (Haskell!) isn’t of any use either. Therefore, Thrill adds certain primitives to its processing engine to make working with immutable data useful: operations. An operation is application of some logic, like filtering or mapping, that’ll not be immediately executed but is there to help Thrill to lazily create directed acyclic graphs for later execution on behalf of an action. An action is also an operation but one that doesn’t return any data. Instead, it triggers the evaluation of the constructed graph. We can imagine operations as “intentions” like “I will select the first five elements from this immutable array, then map them to new five elements…” where actions are more like “…and send them over the network“. There are four types of operations:
- No-Incoming-Data Operations
- One-or-More-Incoming-Data Operations, with two sub-groups:
- Local Operations (LOps)
- Distributed Operations (DOps)
- No-Outgoing-Data Operations: Actions
Because our data is always immutable and no direct access is allowed we can easily chain such “intentions” together and form graphs of any complexity and spread them over a network of interconnected machines. In Thrill’s lingo this immutable data is called DIA: Distributed Immutable Array and can contain elements of any type and is distributed over a cluster in some way, like TCP/IP-based networks. Currently, these operations are available but one can expect more primitives to be added to this list as the project continues to grow:
Generate, ReadLines, ReadBinary
Map, FlatMap, Filter, BernoulliSample,
Union, Collapse, Cache, ReduceByKey, ReduceToIndex,
GroupByKey, GroupToIndex, Sort, Merge, Concat, PrefixSum,
Zip, ZipWithIndex, Window, FlatWindow, Execute, Size, AllGather,
Sum, Min, Max, WriteLines, WriteBinary
Most of these operations are nothing exceptional or hard to grasp as their counterparts can be found in similar frameworks like Spark or Flink. Or just by looking at the syntax of Haskell one can easily spot similar concepts. The harder part, from my point of view, is the understanding of the framework itself and how it wants our code to be structured. Thrill is an execution engine and therefore we have to configure our C++ code properly so it can be executed by its runtime. Because I’m still a beginner and don’t know much about Thrill I’ll use a small example from their tutorial pages and try to describe how I’ve created my own testing environment to automatically build and link my code. The code contains a simple logic that utilizes STL random & ostream headers to generate a random number distribution and print the numbers in the console.
A successful execution is based on a valid Context that describes the environment Thrill runs in and allows us to create DIAs. To create a proper Context we have to begin our code by calling the thrill::Run() method that expects a lambda as a parameter. This lambda function will then receive the Context reference and run on each worker, that is: the machines that execute code in parallel.
Inside our lambda we use the Context reference to call our custom Process() function. This is the moment where our own logic kicks in.
Inside Process() we initialize the randomizer from STL and call certain Thrill’s operations. We Generate() 100 Points by feeding them randomly created numbers and ultimately Cache() them to prevent recalculations. And just for debugging purposes we call the Print() method which uses the previously defined << operator overload.
The start of the execution will yield a result like this:

And it will end with a message like this one:

As I’m using a single machine here your output may be different when you try to run it in a cluster. Now the question is, how do we compile this code? Just including a few include-files isn’t enough. We must compile and link the Thrill library as well. Well, after much experimentation I’ve decided that the most easiest way for me is to integrate Thrill in a sub-directory and point to it via CMake. This way I can anytime checkout the newest version and simply recompile & link my code. The project structure I’m using looks like this:
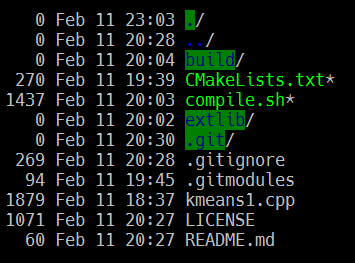
My source files are simply located in the root directory but can be reorganized any other way. More importantly I have an extlib-directory that contains sources of external libraries like Thrill. There’s also a compile.sh executable script that takes care of downloading the latest versions of extlib-sources. In CMakeLists.txt I’ve defined what sources should be compiled and which libraries I want to link my code with. So, if in future some new sources come in, I have only to update my CMakeLists.txt to let them be compiled properly. Also, if some additional externals are needed I simply use this git command:
git submodule add YOUR_EXTERNAL_MODULE.git extlib/YOUR_EXTERNAL_MODULE/
The locations of all known modules can be found in .gitmodules
After each successful compilation the binary lands in build.
Conclusion
Thrill is an “experimental” technology but an interesting one. And more importantly, we can now use Modern C++ tools to create Big Data processing logic that’s being “usually” done on JVM with Scala, Java or even via Python-based clients like PySpark. I know that I could show you only so much as I’m still learning about the basics of Thrill. Despite all the shortcomings, I hope you’ll find Thrill interesting enough to give it a try.
Have fun!




{kind=link}
{kind=link}
{kind=link}
{kind=link}
3 thoughts on “Thrill – Big Data Processing with C++”
Hi, I need command “git init” before “git pull https://github.com/thrill/thrill.git“
Hi Luiz,
Thanks for the comment.
It was my fault. It should have been “git clone https://github.com/thrill/thrill.git” and not “git pull”. I’ve corrected the article.
Regards,
Thanks for the nice article!