
27 minutes read
Building web apps by following certain reactive patterns and conventions is a proven way of delivering stable and scalable software. The tool set we’ll be talking about is known under the acronym ngrx and it comprises of several sub-packages. Here I’ll refer to them simply as ‘ngrx’ but, please, take into account that there are many of them with the same prefix, like ngrx/state, ngrx/effects, ngrx/core and so on.
We’ll develop a simple Angular 4.x app showing a table in master-detail design. The UI plugin used to create the table is the nice datatables.net library.
The sources can be found here.
A working demo is located here.
Project Setup
Regarding project structure and build processes we will follow the ‘standard’ approach by thematically putting everything under src/app and using WebPack scripts. All build scripts are located in /config directory.

To build and run the app in development mode just type in npm run start:hmr. For a final build use npm run build:prod.
Now, let’s talk about the most important stuff in every app: its state. Yes, we all know it, state is hard to manage and extremely hard to manipulate correctly. And from my own experience I’d say that the best way to deal with it is to treat it as something that can’t be changed at all. I think most of you remember the golden days of Backbone, Angular 1.x and other pre-VirtualDOM JS-frameworks where one would write many different event-handlers, two-way data bindings, component inputs/outputs and so on. Sooner or later a change request will arrive by, let’s say, adding a new component that modifies the state in a certain way and your first question would be: Does this new behavior affect other components as well? I think most of us know that questions like these are indicators that we actually don’t know for sure what our app’s whole state is.
Anyway, let’s forget those wonderful days full of event-handler zombies and DOM trashing and start to play with something more sane. Enter Redux.
Redux
Some time ago a new pattern for state management emerged: Redux. It’s a JavaScript library trying to overcome the inherent complexity of the Flux-Architecture that has been popularized by the extremely successful React UI library. In essence, Redux defines a single store where our complete State resides and the only way to change it is by sending certain actions that you define according to your app’s requirements. While the app runs users and other entities, like services, can send actions to inform the store about their intentions which may or may not change the current state. The logic that has to process those actions is called a reducer. A reducer is basically a pure function that takes some state plus an action and returns a new state as a result. The state returned does not refer to the previous one because pure functions will always return a new value. Every reducer call produces a new reference pointing to a new state. In such way the state always remains immutable to external entities. Another popular term is referential transparency. The advantage of this approach is that you don’t have to think about any ‘unknown’ state manipulators that could potentially change the state while you’re trying to do the same. A simple example is the situation where you click a button to save some entry from a Grid without knowing that some formatting logic kicks in at the same time because it reacts to your click-event as well thus changing your data in a destructive way (from your database’s perspective). I’ve experienced such things very often and of course, it was my fault, but at the same time one has to admit: keeping the whole app state in one’s own head is not only very hard but practically impossible. It’s not only some ridiculous click-handlers but very often horribly convoluted logic that spreads over several components and changes the state in unpredictable ways because the same logic reacts differently depending on some (un)known input parameters. These are problems that arise when you rely upon impure functions. You’ll never know what you’ll get the next time.
Now, let’s see in a picture how reducers work:

There are a few important things we have to learn first before we dig deeper. First, the state is at the beginning and the end of each ‘cycle’. The current state determines what a component, a user, a service or anything else can do with the app. But the state is also the ultimate end of every completed action. It is everything in between these two poles that we have to deal with. This is exactly the same stuff we’ve been dealing with for a long long time but now we don’t have to think about any side-effects or ‘invisible’ participants when we’re about to change it. Instead, there’s a clear and simple path we can take to steer our app. We begin with some state and fire an action, which is, by the way, just an instance describing our intentions. The action will then be consumed by an appropriate reducer. There could be many of them but only one of them will process this action. Each and every action is distinguishable from any other. There are no ‘similar’ actions or actions that two reducers will process at the same time as it would wreck our state’s predictability. So, the reducer takes this action and unpacks the type and (optional) payload from it. For example an action could be of type ActionType.ADD_USER and the payload would be some UserClass-Instance. The reducer would then take the current state, create a new one based on its contents plus the User from our action. Then it’d return a brand new state that’s not pointing to the old one. The ultimate result would be a new state as product of a function application: state + action (with optional payload) => new state. This is how Redux works. Of course there are many other extensions and middlewares for Redux that deal with various use-cases but ultimately everything boils down to this simple fact that a state is just a product of some previous state plus an applied function (via reducers).
Ngrx in Action
Ngrx is a set of libraries that implement the Redux pattern for the Angular framework by using the very popular rxjs library as its foundation. This way we can maintain our app’s state by using Observables and Asynchronous Streams. These days it’s pretty normal and most users will even expect that our web apps behave like their desktop or mobile-native counterparts. Therefore, if everything should be done just-in-time and without delays then it’s best to start thinking in-time as well. This way everything becomes a stream of data spread over time and our own solutions will take a different path towards their completion. No more spatial arrays filled with data waiting to be for-eached or while-doed by some logic of ours. No more callbacks or promises that can only deal with single values. Instead, we observe data streams containing many or even infinite entries that come in at certain points in time. We consume, filter, manipulate them, or even generate new ones based on previous streams. And we do this immediately, by using declarative methods thus minimizing imperative coding parts to just a few, if any. But, let me stop here, as I really don’t want to throw buzzwords at you because there are already some folks who do this much better (or worse?) than me. What’s important to know is that our State and everything we do with it ultimately becomes a stream of data located in time. It’s not only that we have a single immutable state but it’s also an observable one. And to make use of it we will follow the above picture by creating a set of Actions that describe what we could do throughout app’s life time.
Actions
Actions are pieces of information that contain data which could modify a store. An action comprises of two properties, namely its type and an optional payload. The type is there to show what kind of change should happen inside the store. It’s usually a unique string whose variable name is often written all-caps like USER_ADD, USER_REMOVE, USER_SAVE etc. Often you’ll see that action strings also contain a prefixed Category information. This can help you filter and sort different actions more easily in situations when you have to read massive logs that contain many of them.
Here we declare an interface describing the actions and also export them as already configured types. The variable CATEGORY is a string we define according to our app’s structure.
Actions are not only indicators about what has to be done inside the store but they’re also carriers for data that’ll be used to change the state. Therefore we want to define classes that implement the Action interface so we can later create proper instances. Below is how our implementations look like. We use straightforward semantics for naming them to indicate the kind of action being applied and what type of payload it should carry with it. The above INIT action, for example, we define as InitCustomerAction and give it an appropriate type and payload. The same happens with INITIALIZED, INIT_FAILED and other actions as well. The scheme is the same and the only difference is if it accepts a payload or not. For these who expect a payload it will be of type ICustomer that corresponds to the data shown in our table.
Finally we group all of the above actions together and form a single type called CustomerAction. This will later help us define our reducer. Our app is rather small so there’s no obvious advantage of creating a Union Type. In real-world applications however, with many reducers and lots of different actions, union types quickly become helpful tools to group thematically related actions together.
Our first step is now complete. And before we go any further I’d like to point out one very important thing that’s often left unnoticed: Actions not only describe things that could be done for now but also help you think about future possibilities. They’re a tools for thought. I see actions not only as code but also from a more philosophical point of view as they help me understand my own app! Yes, it’s like in the good old Matrix movie where you should not try to manipulate the spoon but yourself instead. Assumptions, prejudices, false impressions and misunderstandings are everywhere, so there’s no reason to believe they couldn’t poison your software as well. Therefore, try to avoid or at least to overcome them by thoroughly thinking about your future software. Will it always do these few things you assumed at the beginning of the project? What would happen if your customers ask you to implement this one ‘small’ change? Will your app happily incorporate the change? Or just explode a few days later? So, think about your app first. And actions are very helpful tools to illuminate all the possible paths your software may take during its lifetime.
In the code above we’ve defined certain actions that may happen to data describing a single customer. We see our future customer entries as things that could be initialized, changed, deleted or persisted. But also we take into account that things could go wrong, so we define an action that takes care of initialization failures. This is how we think about our app by using actions as our compass.
Action Creators
Although we could send raw actions to our reducers it’s recommended to write small mechanisms that’ll take care of their proper instantiation. It also looks much nicer without the ugly ‘new’ operator. At least this is how I think about action creators. An action creator is just a helper class that’s being used to create an action instance that can be dispatched. But in case of ngrx action creators are a little bit more. They’re also Injectables that could be provided via dependency injection by the framework itself. If you want to know more about Injectables there’s an older article of mine that may be of some use to you.
Here, we do nothing else but instantiate and return all available Actions depending on the method being called. For every raw action there’s a corresponding action creator method. Later, when we dispatch actions to the store we’ll see why it’s better to use action creators than raw actions. Now, as we have our actions and action creators set up it’s time to write our first reducer.
Reducers
As already written, reducers are pure functions. This means that they return values only depend on their current parameters. There’s nothing else that could change the returned value for the same set of arguments between two calls. Just like in math where functions always expand to same values given the same operands, reducers return the same state that only depends on their current input parameters (actions). A reducer must always be called by passing the current state and an action. It there’s no state then a predefined initial state will be used instead. This initial state could even be an ‘undefined’ but it has to be some state. Usually reducers implement a switch-statement that executes certain code paths depending on the action type. In our case the reducer looks like this:
As expected, our reducer takes a state of type ICustomerState and some action of (union) type CustomerAction. Now, before we dive in, just let me clarify what this ICustomerState is. It’s a description of a part of a complete application state. ICustomerState is not the complete application’s state, as it only describes a certain aspect of your whole application’s state. Therefore, one should see interfaces like these as elements that describe only parts of your general app’s state. You can just look at the first case in the above switch statement to recognize it. Do you see that the construction of a new state is a call of:
So, there’s already a state, whatever it may contain, as we don’t see it’s whole structure and also don’t care. We’re only modifying a certain part of it, namely the customer. Then we put everything together by assigning it everything to the new, empty Object {} and return it as a new state. This is how we change the state without affecting its other parts of it while simultaneously keeping it immutable to outside consumers. But we also see that not all of the possible actions will be processed by our reducer. Why? This is because not every action is supposed to change the state. For example, the action carrying the information that customer data has been changed can’t be processed by the reducer in a meaningful way. At least not in our app. But, there might be certain parts in our app that could indicate such changes, like tooltips for example. You change some customer detail and a warning popup appears informing you that the changes are currently only locally available and should be saved in the database as well. Such actions that don’t change the state of the app should also not be processed by the reducer. But you may want to use them to change the behavior of your app that’s not bound to the current state. Showing a popup, disabling a button and other elements could be possible consumers of such actions.
Application State
As already mentioned our application state comprises of many possible sub-states. In our case we’ll have only one but you can easily imagine how it would look like if there were many other sub-states, like orders, products, invoices etc. For each state you’d have to define a proper sub-state interface and a set of corresponding actions and reducers.
They all define what we call the application state. Subsequently, we combine all of the reducers into one meta-reducer so the incoming actions can be forwarded to all available reducers. And only those who care about a particular action would, well, take an action and change the state.
This is how the actions fly throughout the application. One could think of a funnel where all possible things fly into our app trying to change its behavior (state) in some way. Further down the funnel the actions fly though the available reducers reaching their ultimate end: a reducer that understands them and (possibly) combines their payload with the current state returning a new one. Additionally we define two helper methods just to make the handling of Observables and Subsriptions easier. These will serve us as tools to extract certain parts of the state. One could also write code without them but then it’s mandatory to write lengthy subscription-calls like:
this.store.select(appState => appState.mySubState).subscribe(subState)
Not funny and it looks rather ugly.
Dealing with Side-Effects
Being functional is nice and perhaps even cool these days. However the world itself is very real and real-world apps usually change the world in some way. They do have an impact on it by side-effecting it. If the world was pure like math I’d wouldn’t be writing this. I doubt we’d exist at all. However, this is higher philosophy so let’s keep it more practical. What about side-effects? What if I have to change some state by using an impure function? For example, by calling a REST service or calculating some values that randomly change over time. How to incorporate such logic into our previous pure functions without losing control about the overall app state? Well, there’s an elegant solution for this called ngrx/effects. The construct @Effects provided by this library is, as I understand it, based on Monads. Yes, I know, there are fairy tales about people who somehow get to understand them but immediately lose the ability to explain them to others. For my part, I can only say that I’ve also written an article on Monads in Scala, and I deeply regret it now. Partially because of Scala but also because it makes little sense to explain Monads without using a really practical example. Now, to keep it as simple as possible, just think of a Monad as a construct to do some extra work, whatever it may be, and still get the value of same type as if they wouldn’t exist at all. The data you get would remain the same even if you’d later remove this Monad, for whatever reason. For example, if I want to get some customer data that contains the “active debt” then the only thing I care about it this customer data as a whole. I don’t care about how it gets its “active debt” calculated. This could be by calling a service, or calculating it on the fly, or whatever else. I really don’t care. Even if the calculation fails I’d still get some meaningful response. And if in future I remove this Monad because all customers will from now on have their “active debt” persisted in the same table (just because I really don’t care about my database structures) then who cares, just give me my customer’s data like before. This is the reason why @Effect() exists. We want to integrate side-effecting execution paths into our app without letting them lead us astray. In our case we want to wire up some side-effecting code that should be executed when we select a customer. In our example we’d like not only to show customer’s personal data but also its picture and active debt. This is how our @Effect looks like. First, we recognize that we’re dealing with an @Injectable again, just like with Action Creators. This is nice as we can expect it to be delivered by Angular’s DI itself. Also, it can be instantiated with other dependency-injected instances as well. Here we want our Effects-handling instance to have two services delivered by Angular’s DI, Payment & Images, and also to get a reference to our own Action Creators Injectable. This means that we’ll not only consume service responses but also generate new actions as well. I suppose you already suspect what we’re about to do.
Our applications are mostly full of life, because there’s always something happening right now, either via user interactions or by some automatized logic. Its not a surprise that behaviors like these generate actions which can be intercepted not only by reducers who directly change the state but also by Effect-handling Instances that don’t change the state directly but integrate additional execution paths. Here, our Effects instance reacts to the SELECTED action and subsequently calls two services that ultimately to fill the payload with two additional parameters: picture and active_debt. Afterwards, we create a new action by our Action Creator and dispatch it. And the process continues as if nothing side-effectful has happened. This is the whole magic. It’s really just a Monad. You simply take an already known execution path, like the one reserved for SELECTED actions and add some detour to it but without changing its default destination: the INITIALIZED action whose ultimate goal is the initialized state.
Using ngrx
I’m not going to steal your time by talking a lot about proper Angular project configuration or build scripts. There are already a few articles of mine you can fine on the right side of this blog. I’ll also avoid talking much about the configuration of the nice datatables.net plugin as there’s already an article that describes in detail how one can use it in a project. Instead, we’ll jump directly to the point in our app where we dispatch an action and follow it until it reaches its ultimate destination.
In the above code example we’ve wired up our dispatch method to our table’s own select event-handler. Inside we see a new object instance called ‘store’. This is nothing else but our previously defined store that contains, among other possible sub-states, our customer’s state. And just like other Injectable instances our store can be provided to all of our components via Angular’s dependency injection. We simply refer to the ngrx/store package and specialize its instantiation with the IAppStore interface. There’s nothing else to be done to get a proper store instance inserted. Angular in combination with ngrx makes it really easy to communicate with our application’s store. And because we’ve defined a proper Action Creator we can immediately utilize its helper methods to generate Actions. In this case we’ve selected a customer row that we want the store to know about. Luckily, there’s a method that creates an Action instance which expects a customer instance. This is all that has to be done. We only generate a SELECT action without caring about what’d happen next. If you’ve carefully followed this article you’ll now recognize what could possibly happen next. Just visualize an action of type SELECTED flying though the application. And there’s also a watching @Effect handler that reacts to actions of this type. Let’s fire a debugger as in the screenshot below.
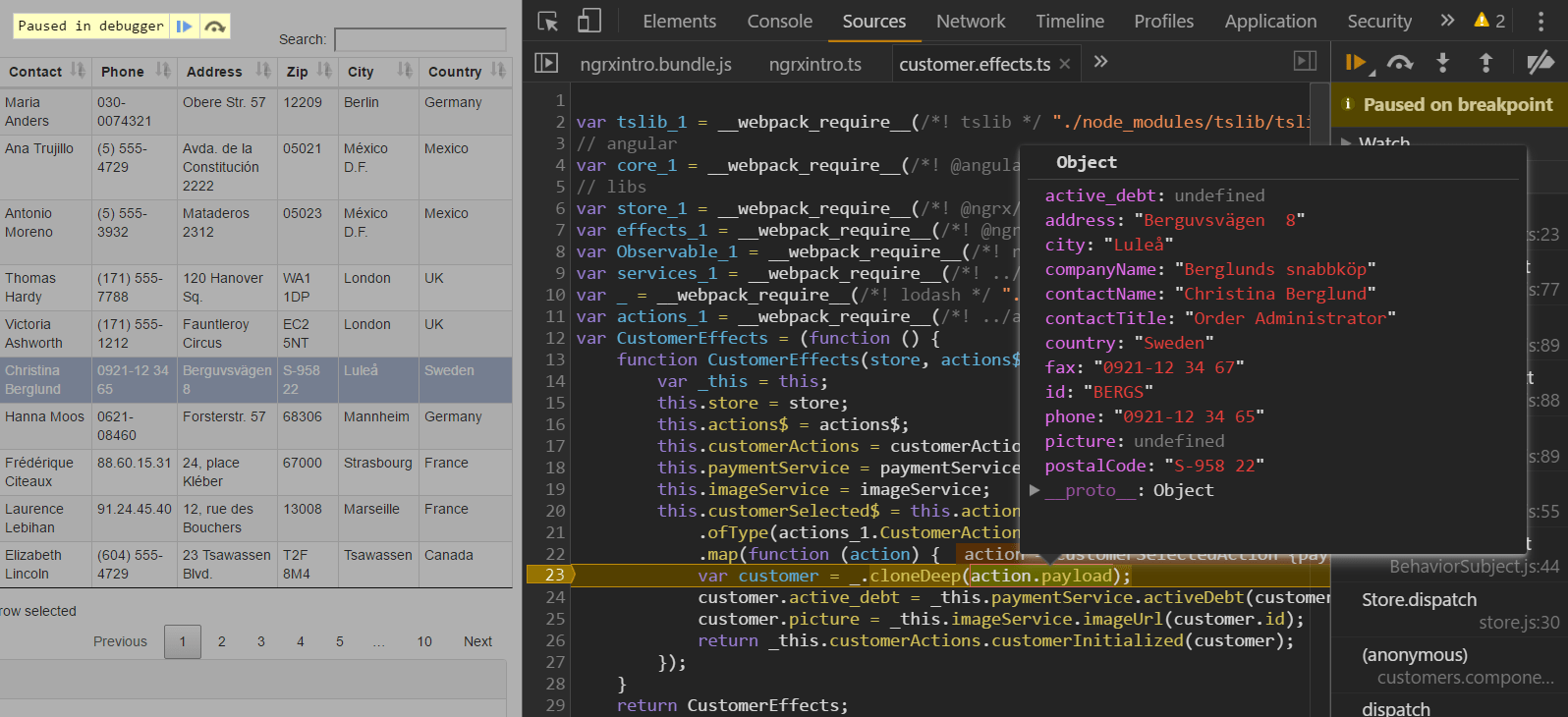
Here we see that the incoming payload (our customer) has no data in the two fields we’re about to manipulate. In the end the Effects handler will dispatch yet another action indicating that the Customer instance is now initialized. This action belongs to those that our reducer cares about. In the screenshot below we see that our object now has all data filled in:
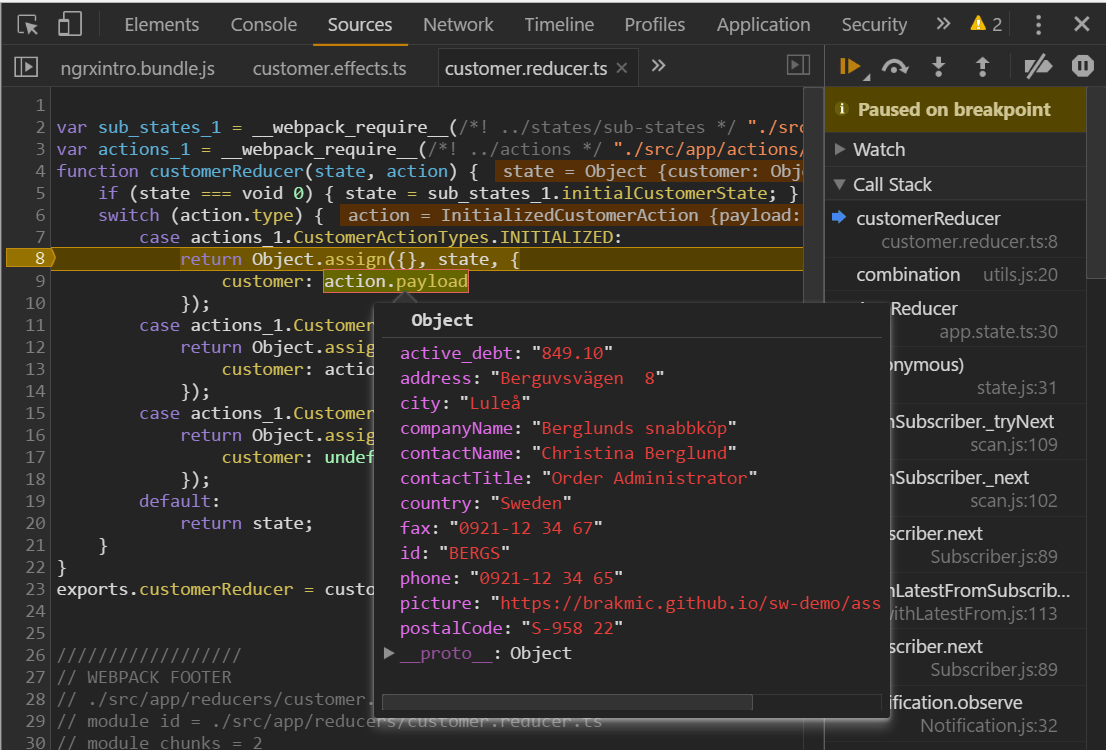
I’m sure you can now recognize the data flow and how this structure works. A reducer cares only about certain actions and does not participate in object creation or manipulation. For such things, as they’re highly side-effectful, we have @Effect handler instances.
Reacting to State Change
Now the next question is how do we react to a state change? What should the UI do? Where does its data come from? Well, do you remember the two helper methods from the state definition source? Now it’s time to use them to get the Observable instance of our Customer data.
It’s as simple as this. We declare an Observable<ICustomer> and then let the helper method extract the respective sub-state that contains it. Without the helper method we’d would have to write a longer method call or call-chain that’d look like this:
The result would be a concrete Customer instance and not an Observable. Therefore you’d have to remove the async pipe from the template as we’re using it here to subscribe to Observables and return their latest values. Whichever way you might take the result would be the same: the last component in chain, InfoComponent, will take the incoming data and show it in a panel on the right side. This component knows nothing about the whole journey taken from the very first click that went through Actions, Effects and Reducers. This is how one can control and maintain state without inadvertently affecting unrelated application’s parts. The example above is very simple but the real power of this approach lies in the fact that it’s very scalable no matter how many different actions and state-changing actors you might later add to your app. As long as you follow the rule that nothing except reducers is allowed to change your state and that all side-effects belong to their @Effect watchers, your application will stay manageable and you’ll avoid the dreadful loss of control.
Conclusion
Writing such a lengthy article is a risk because we live in times of TL;DR; However, managing state is still one of the most important things in computing and it took me a considerable amount time to understand that no matter how hard I may try the state will ultimately break out and leave my applications mortally wounded. I may sound overly dramatic but touching a state directly is something one should rather avoid. There are better tools than one’s own memory. We, developers, may be joking about job security and how it can help us keep our jobs if we’re the only ones who really understand all aspects of some applications. However, one day the state will break out and then you’ll be forced to realize that being alone in such a situation is not a pleasant experience. Therefore, we should use these patterns not only as a way to think about our apps but also to communicate them to others. The more people know about your app, intentions and plans the greater the chance they’ll see things you don’t recognize for now. And this will surely help you write better apps. And better apps also mean happier customers. And this is what our business is all about.


{kind=link}
{kind=link}
{kind=link}
{kind=link}