
16 minutes read
It’s been a while since I wrote my last article. A Big-Data Sorry to my “massive” audience.  Actually, I was planning to write a follow-up to the last article on Machine Learning but could not find enough time to complete it. Also, I’ll soon give a presentation in a Meetup (in Germany). A classical example on what happens when you have to complete several tasks at the same time. In the end all of them will fail. But I’ll try to compensate it with yet another task: by writing an article about the brand-new Apache Flink v0.10.0 and its DataStream API. 😀
Actually, I was planning to write a follow-up to the last article on Machine Learning but could not find enough time to complete it. Also, I’ll soon give a presentation in a Meetup (in Germany). A classical example on what happens when you have to complete several tasks at the same time. In the end all of them will fail. But I’ll try to compensate it with yet another task: by writing an article about the brand-new Apache Flink v0.10.0 and its DataStream API. 😀
As always, the sources are on GitHub.
What is Apache Flink?
Well, if you already know Apache Spark then the definition may be fairly similar: an open-source platform for distributed stream and batch data processing. However, there’s one striking difference: Flink is a real streaming engine while Spark only can use so-called “micro-batches”, even when doing stream processing. This means that with Flink you always access the data in-time without pressing an “invisible PAUSE button” to halt the stream and cut it down into small pieces (“batches”), as it happens with Spark. For Flink everything is a stream, even when you’re doing batch processing. Flink sees batch processing as a special case of the more general stream processing philosophy. However, I’m not blaming Spark here (honestly, I neither know Spark nor Flink very well) but if you’re into real-time stream processing then you should give Apache Flink a try. So, what is Apache Flink? First, the name itself is not English but German and means “swift” or “agile”. It’s a project originating from TU Berlin, HU Berlin and Hasso Plattner Institute Potsdam and the original name was “Stratosphere” but later was dropped because of some trademark/copyright issues. It started in 2008 and is based on the ideas of Prof. Volker Markl. For more details about the project’s background and the overall idea read this interview. Some time later a few people from this project created a company named data Artisans located in Berlin. Everything I know about Flink is based on their nice docs and courses one can read for free. Therefore, all possible errors and misleading explanations in this article are mine. Additionally, you may be interested in some of the videos from the Flink Forward 2015 Conference held in October.
The Flink Stack
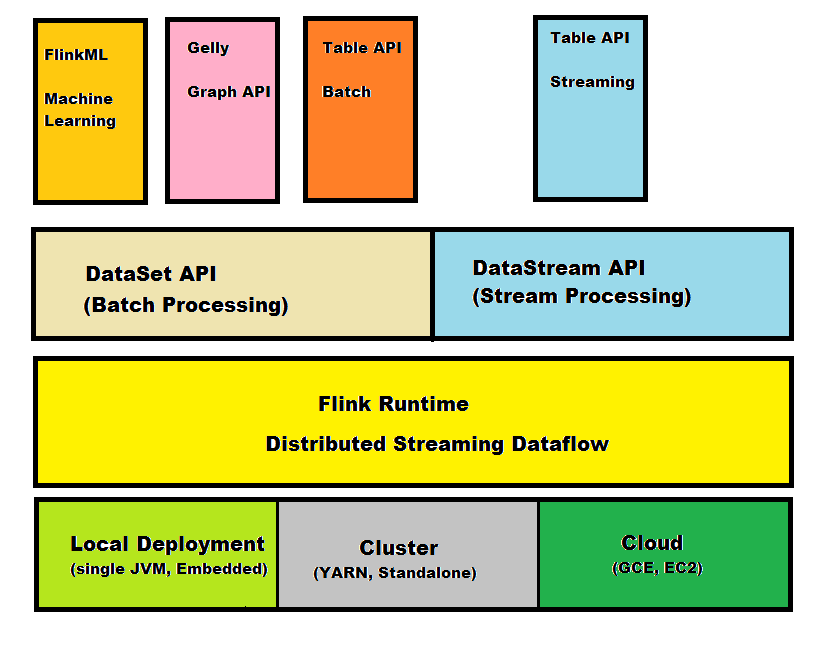
The Flink Stack is based on a single runtime which is split into two parts: batch processing and streaming. There are many important designs which constitute Flink, like:
- Stream-Processing is the core of Flink. Batch-Processing is only a sub-type of Stream-Processing
- Flink implements its own memory management and serializers
- Exactly-once semantics for stateful computations in streaming applications
- Supports different cluster management systems and storages
- Provides a highly modularized API comprising of libraries for Machine Learning, Graph Processing, Tabular Data Processing etc.
Execution Model
One must admit that Flink is very good at hiding internal complexities. This is, of course, very helpful when you start learning Flink but it can also lead to many false assumptions. For example, the fact that we can easily create apps and deploy them almost instantly on even complex structures like clusters could lead us to wrong assumptions about Flink’s execution model. What happens with an app after we’ve sent it to Flink’s JobManager? Does Flink simply execute apps simultaneously on all available clusters? Of course not. Instead, Flink’s Optimizer analyzes the app and creates an “Execution Plan” which is then compiled and executed on many machines. Flink does never “grab a program” to execute it immediately. The advantage of this strategy is that even the most complex application structure can be broken down into smaller, more manageable, parallelizable and serializable parts. Remember, Flink implements own serializers and does it’s own memory management which avoids the extremely costly and rather slow JVM Garbage Collection. When looking inside the memory management of Flink one could easily spot many similarities to C++ way of resource management (this means: playing with raw bytes). These few sentences are, of source, everything else but “sufficient” to describe Flink’s internals in detail. My intention is just to make it clear that Flink does much more than “just” executing our program logic over many machines. Maybe I’ll write a follow-up article to focus in greater detail on these important parts (memory management, serialization, execution model etc.)
Installation
The installation of Flink is pretty easy and only needs a simple extraction of the downloaded package. However, you should have a JDK (Java Development Kit) installed and point the system environment variable JAVA_HOME to it. You need a JDK because we’ll also write a small Twitter-Streaming Application that’ll be deployed to a running Flink instance. For this article a simple stand-alone environment of Flink is sufficient. If you want to use it with Hadoop, for example, you can either compile Hadoop’s sources or download pre-compiled versions. I’m using Windows here and know how hard it can be to (not only) install Hadoop on it. Therefore I’d recommend you to download pre-compiled binaries for Hadoop from this site. If you prefer a POSIX-like environment under Windows, Cygwin may be a nice solutions. But beware, running scripts from Cygwin can often lead to pesky errors regarding line-endings which are different on POSIX and Windows. As a remedy just insert these two lines in your .bash_profile (or your shell’s profile if you don’t use the standard Bash):
export SHELLOPTS set -o igncr
It basically instructs the shell to ignore carriage-returns.
Starting Apache Flink
Flink supports different environments ranging from simple local installations to complex clusters based on YARN, Mesos, Zookeepr etc. To get in touch with these scripts we list the content of the bin-directory inside Flink’s root.
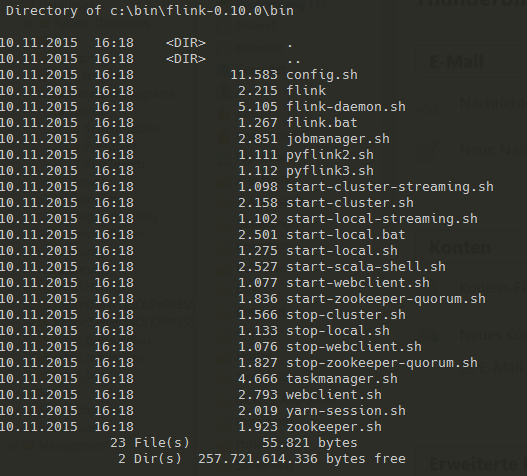
When Flink starts several components will be initialized automatically:
- JobManager (this component controls the whole Flink system and runs in a separate JVM)
- TaskManagers (these components are spread throughout the cluster architecture, each in its own JVM)
To start Flink locally just execute start-local.sh respective start-local.bat. In this case JobManager and TaskManager will run inside the local JVM.

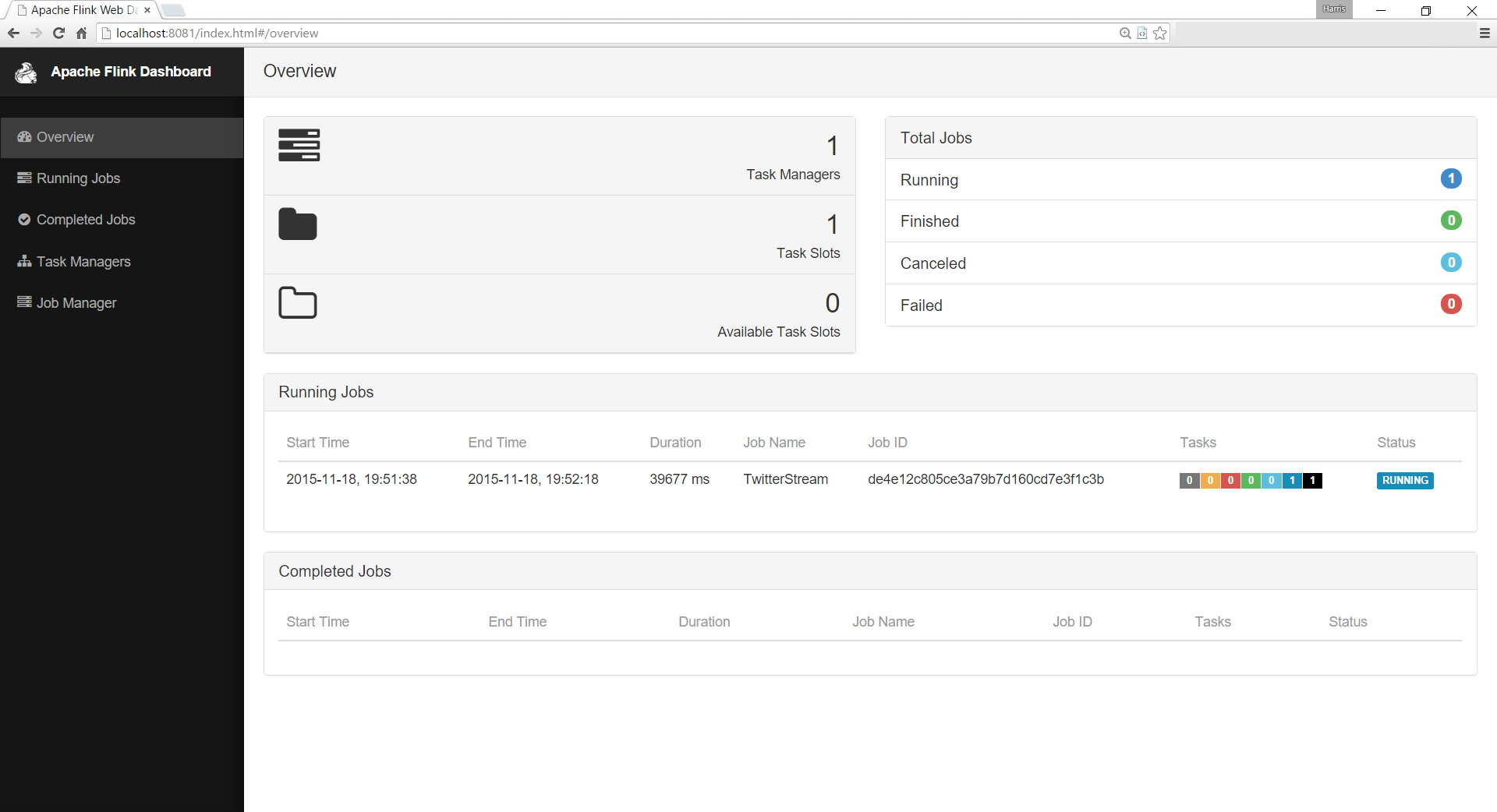
You’ll get a simple info regarding the URL of the management interface. But this interface is not some simple Web-Page where you can see and control your Jobs. It’s actually a fully-fledged WebApp with all the goodies you’d expect from a “modern” WebApp. It’s even mobile-friendly. Being a JavaScript developer I always appreciate when such complex applications not only offer a web-interface but a “usable” one. And these days one shouldn’t use a Browser to support complex tasks without applying modern standards (that is, mobile-friendly, state management inside the app, proper client routing, UI-updates without page-refresh etc.). Of course, all this isn’t directly connection to the primary task of Apache Flink but using such a powerful engine is way easier and more fun when done via a professionally built WebApp. In this case the Apache Flink team did a great job by using AngularJS 1.3.x and some UI libraries like Bootstrap, D3 etc. to develop their management dashboard.
Using DataStream API to receive Twitter-Feeds
In this article we’ll utilize Flink’s DataStream API to consume Twitter-Feeds. To achieve communicate with Twitter’s APIs we’ll use a library called Twitter4J which is originally written in Java but because our code is written in Scala there’ll be no problems to reuse Java classes. If you’re new to Scala maybe this small tutorial of mine could be of some use to you. The Twitter-Stream project is written with IntelliJ IDEA Community Edition and utilizes Maven as its build tool. I’ve used the standard template for Flink projects which is generated via Maven. More info on initializing Flink projects can be found here. To create a skeleton project with all needed references, variables and libs you have to use Maven with this command:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=0.10.0 \
-DgroupId=org.apache.flink.quickstart \
-DartifactId=YOUR_PROJECT_NAME \
-Dversion=0.1 \
-Dpackage=YOUR_PACKAGE_NAMESPACE \
-DinteractiveMode=false
Here’s an example output after a successful project creation.
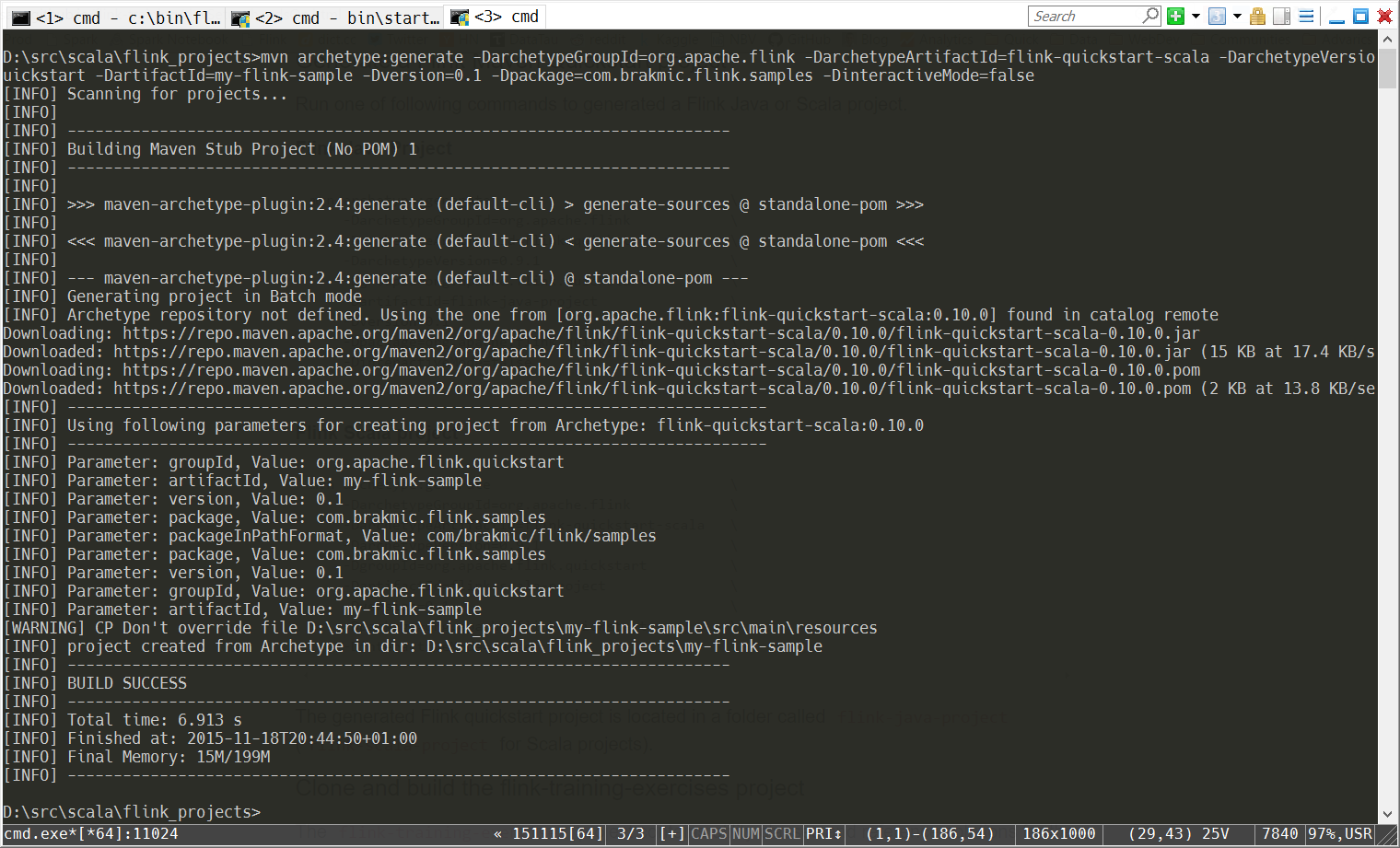
As we see Maven automatically downloads all the needed artifacts and jars. Ultimately, the project will comprise of a pom.xml file describing all dependencies and other settings as well as the project structure inside the src directory. Within src you’ll find directories for Java and Scala sources. We’ll now use IntelliJ to import a Maven project which looks like this:
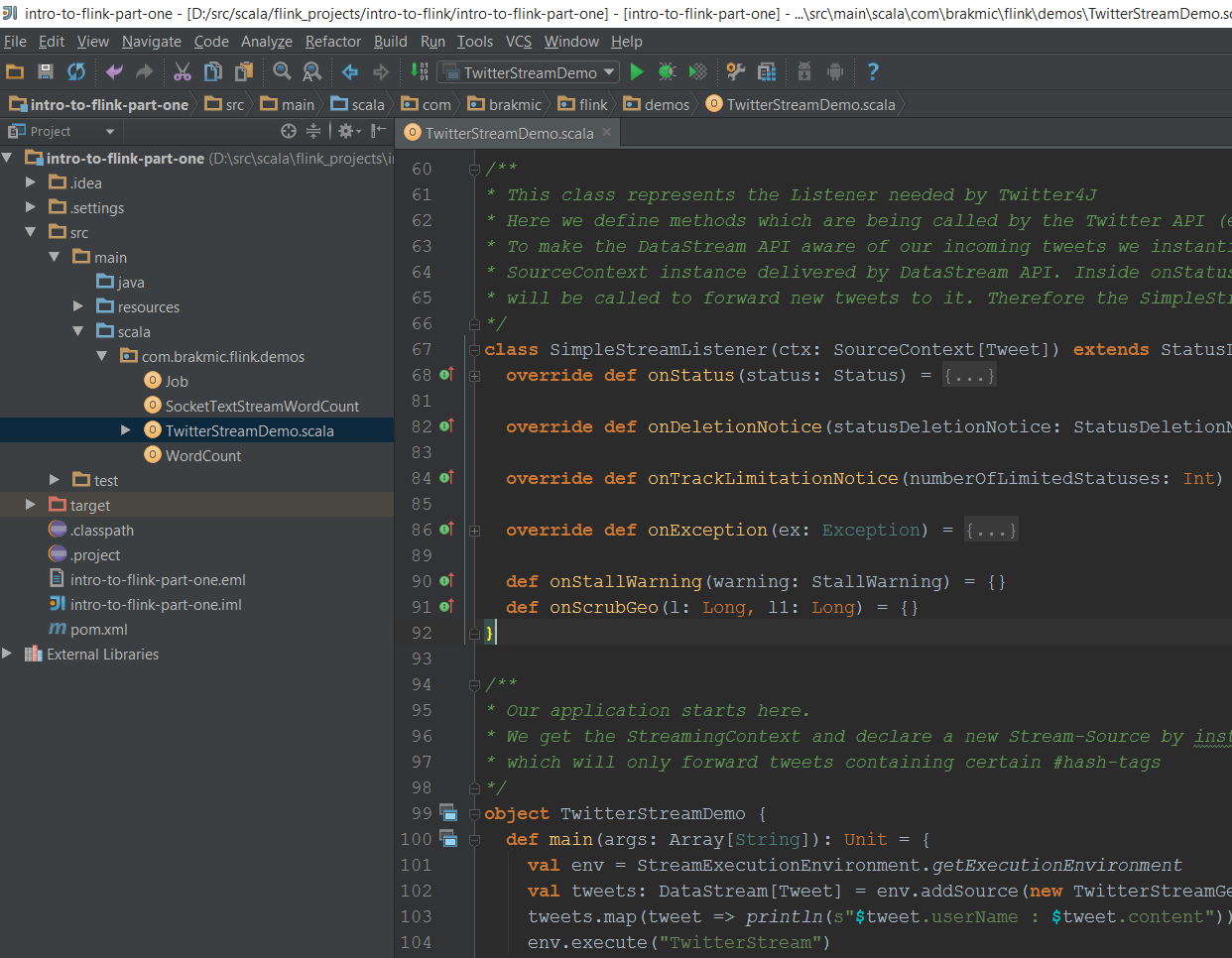
As you can see there are several sources inside the scala directory. Only the TwitterStreamDemo.scala is written by us the others are from the automatically generated Maven project. Our application has to combine two very different types of streams: Flink Streams which expect us to implement certain interfaces and Twitter-Streams that must be handled separately (OAuth logins, Filtering etc.). Therefore we’ll divide our app into several smaller classes/objects:
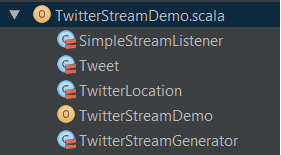
I’m not saying that this is a very good way how to separate logic and of course, you should not put everything into one file. However, this is just a demo so it makes no sense to create several files just to make the project look “professional”.
The Streaming Environment
To be able to work with streams under Flink you need to get proper APIs. This is done by using the StreamExecutionEnvironment

The method getExecutingEnvironment does all the heavy lifting regardless if you run a local Flink instance or connecting a cluster. The next step is the inclusion of a new Streaming Source which in our case will be a Twitter-Feed. Now, the first problem we encounter is the communication with Twitter itself regardless if we’re planning to use this stream in Flink or anywhere else. The second problem is how to make Flink accept the raw Twitter-Stream. Flink defines a set of Interfaces one has to implement to become a valid Flink-DataStream and the original Twitter-Stream is surely not implementing such interface in advance. Therefore, our first task is to get a raw Twitter-Stream.
Receiving Twitter-Feeds
There are many libraries and other options regarding Twitter and consumption of its feeds. In our case we’ll be using the Twitter4J library, originally written in Java. Because we’re using Maven to manage our dependencies a simple entry in pom.xml will automatically inject all needed libraries.
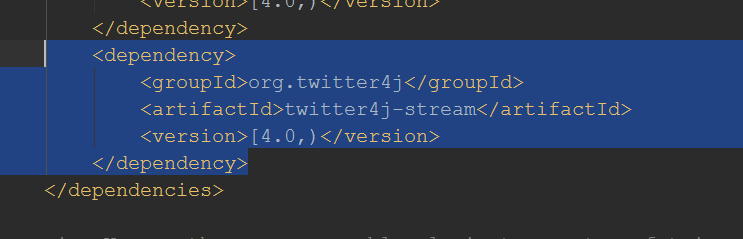
To get the latest versions of Twitter4J an entry in repositories is needed:
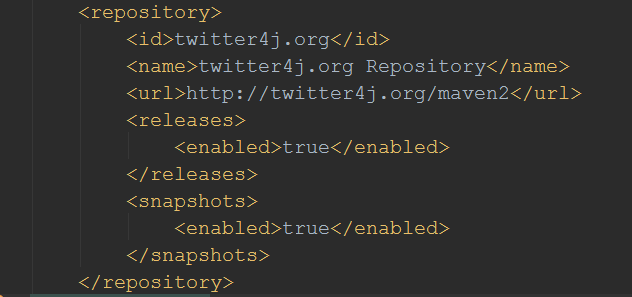
Maven will automatically download the packages after we save pom.xml. To connect properlyx to the Twitter-API we need a developer account and certain keys. If you have a valid Twitter account just go to Twitter Development Pages and register a new app. In one of my earlier articles I have written in detail on how to register an application and where to get the OAuth keys. We will need four keys: Consumer Key, Consumer Secret, Access Token and Access Secret. We’ll put them into the run() method of TwitterStreamGenerator:
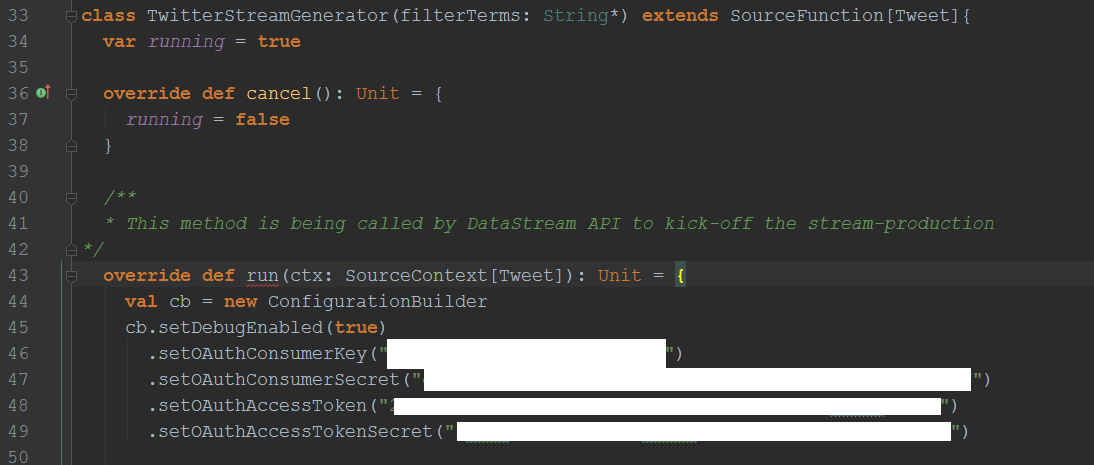
This, of course, is not a must and surely not something you should do in a professional application. In such environments consider using external property-files, for example. Twitter4J offers several options regarding key management and configuration. As we already know, the TwitterStreamGenerator class will provide the Flink-compatible Stream. Therefore it implements the SourceFunction[Tweet] interface. The Tweet Type is just a simple container representing a single Tweet. Because the SourceFunction is general we are free to define the type which will be produced by the instance that implements our SourceFunction. Therefore our TwitterStreamGenerator implements the SourceFunction overriding the methods cancel() and run(). The cancel() method is here just to change the boolean value of the running property. In run() we use our keys to connect to twitter via Twitter4J. It’s not possible to manipulate the Twitter connection outside the TwitterStreamGenerator. Therefore we could easily replace Twitter4J with any other Twitter-Client-Library. Flink doesn’t care much about how we get the data as long as we provide it via well-defined interfaces like SourceFunction.

Our new TwitterStream instance utilizes its own Listener which is not important to Flink but without a proper Listener we couldn’t get any Tweets in the first place. Before we make Flink happy we have to keep Twitter happy first. Here we define a SimpleStreamListener.
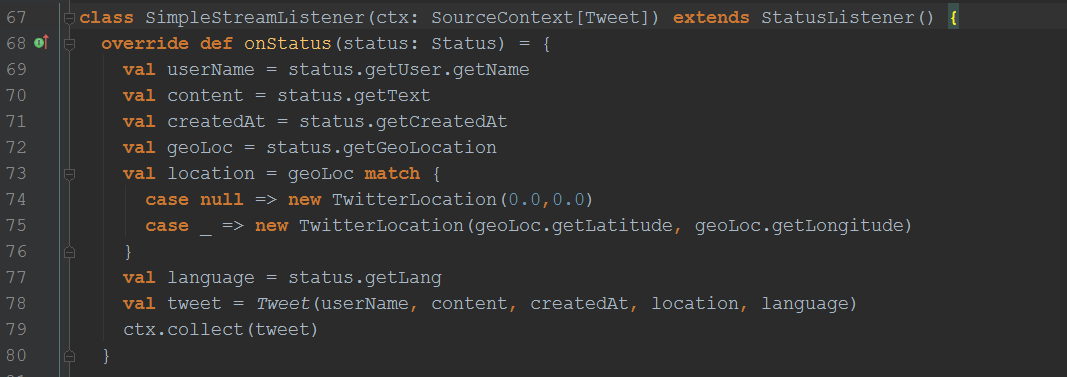
There are several methods one could implement when writing Twitter-Listeners. In our case we only care about the onStatus() method because there we’ll get our precious tweets. Despite its name our Listener is not that simple. Unlike many other listeners this one expects a SourceContext as its constructor argument. This context comes from Flink and serves as a communication channel between Flink and the outside world (as they write in their docs). We’ll use this context to feed it the newly created Tweet-Instances. I assume you already have notices that the type of SourceContext[Tweet] is the same as the Tweet-instances created inside onStatus(). This is the connection point between raw Twitter API and DataStream API. All incoming tweets will be forwarded to the context via its collect() method which is called each time a new Tweet-instance get created. It’s important to know that calling the collect() method triggers the execution of the whole operation.
Processing Twitter-Feeds
The next step in this chain is the processing of newly created Tweets via DataStream API. Here we utilize the map() method provided by our DataStream instance to print out the sender and the content of each received tweet. And finally, to kick-off the whole process we start our engine by using execute(). This is just a simple example with map() where nothing extraordinary happens. But you could easily extend the logic by adding more sophisticated filters and transformations available in Flink.

To start the environment inside IntelliJ open the context menu on TwitterStreamDemo.scala and select Run:
The output in your console would be similar to this:
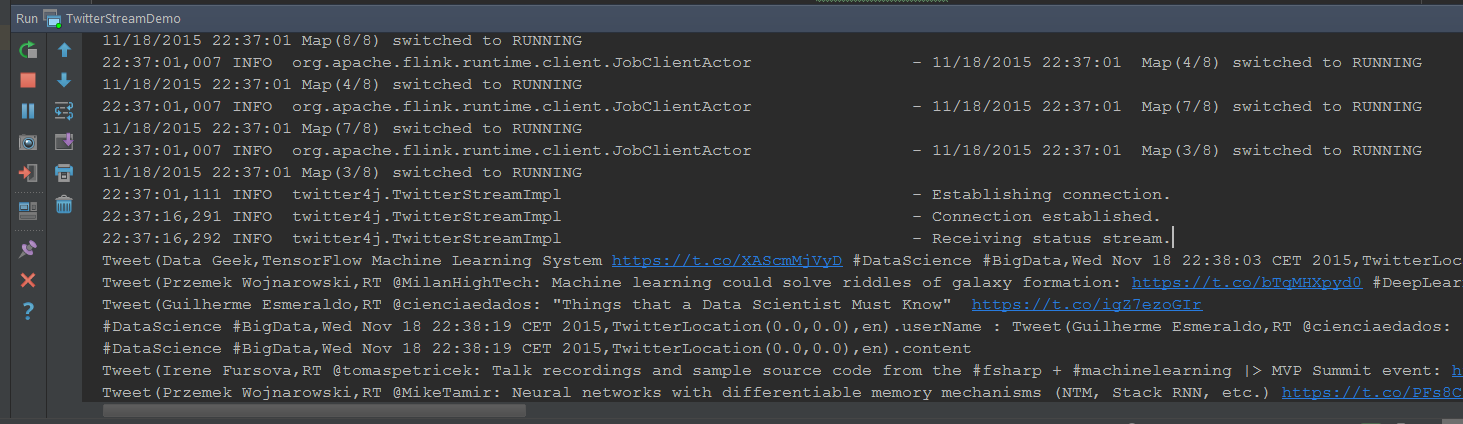
This is nice but not enough. We want our little app to run on a real Flink architecture. Well, not in a cluster but at least something that’s at least not a debug console.
Deploying the TwitterStream-App to Flink
First, we need a running Flink instance. A simple start-local.bat respective start-local.sh from within the bin-directory inside Flink’s root would start such an instance, like already demonstrated at the beginning of this article. Second, we need a proper JAR-file that contains our application. We could generate JARs with IntelliJ or any other IDe but we should also know how to do it via console. Just open your preferred console and go to the root path of your project. Type in
mvn clean package
and you’ll see the output similar to this one:
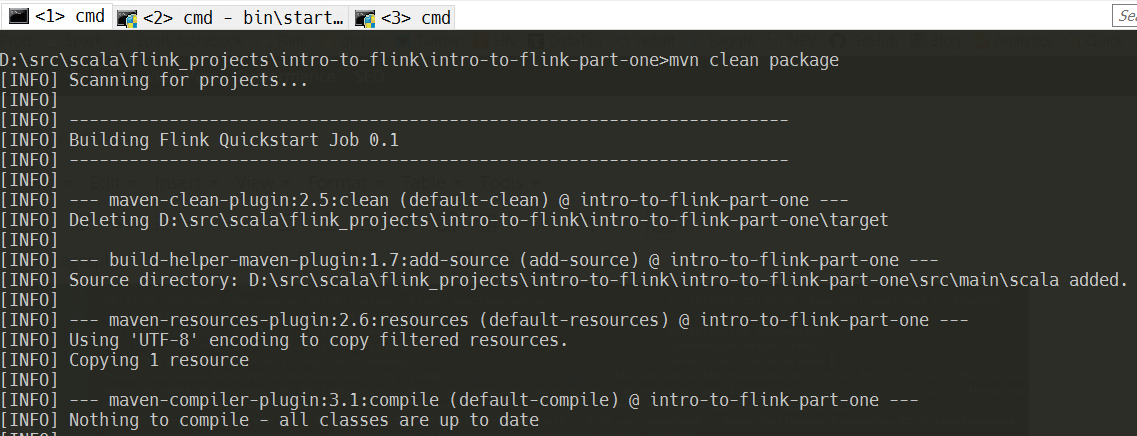
The new JAR-file is located inside the target-directory:
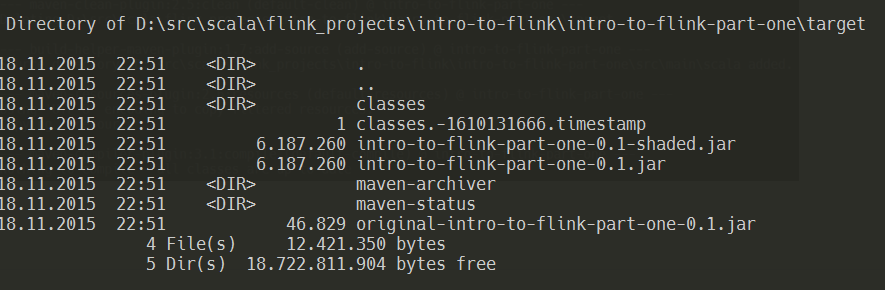
Finally, we deploy the JAR to the running Flink instance by using another script from Flink’s bin-directory:

We use flink.bat respecitive flink.sh with these flags:
- “run” to indicate that our JAR should run on a Flink instance
- “-c” together with the fully qualified class name of the starting Class
- the JAR-file path
If everything goes well the returned information will report that our Job has switched its state from scheduled to running. Now we can check the state of our application via Flink’s Web Dashboard.
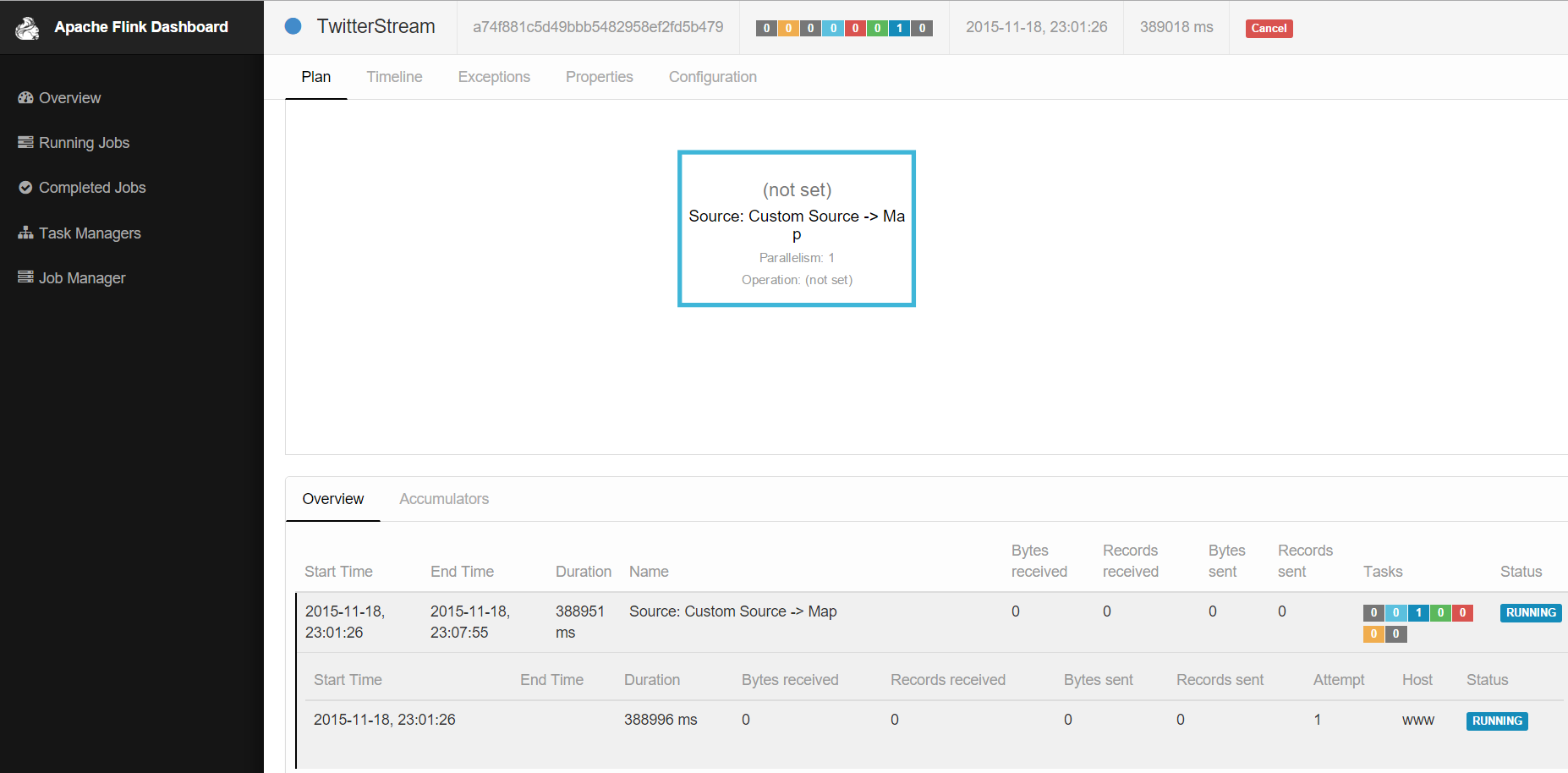
Conclusion
Apache Flink is a new, fast moving platform but nevertheless: the future of distributed computing is based on streams. The same shift we already see in programming languages, so it’s not a big surprise to recognize the same effects in the architectural domain. Many of us are busy replacing older programming logic based on hard-wired class-hierarchies and “data at rest” with newer, more functional code and “data in motion”. We now more often think about our data as something that moves quickly and can change its shape at any time. As a natural reaction to these changes our programming logic now provides more sophisticated toolsets adjusted for stream processing, lazy evaluation, transformations etc. Closely following these trends the architectural domain changes as well. Streams are everywhere and no data is “slow” or “resting” anymore. These days being “flink” in data processing is something that can decide the fate of a whole company. Apache Flink is a wise choice for all of you who have to deal with fast-moving data, distributed computing and stream processing.


{kind=link}
{kind=link}
{kind=link}
10 thoughts on “Stream Processing with Apache Flink”
Hi Harris,
Thanks for your effort of writing this article.
I wrote some ‘Hello world’ programs in Flink few month ago and it seemed for my like a Spark copy (at least in its API).
Was nice to find out from your article that its engine is based on streaming and that Flink API hide all this complexity behind.
Hi Tudor,
Many thanks for your kind words. Indeed, Apache Flink hides much of the complexity behind a friendly API that abstracts away the differences between Batching and Streaming.
Regards,
Harris
Hi, what is the reason of twitter4j usage instead of org.apache.flink.streaming.connectors.twitter.TwitterSource?
Hi,
There’s no explicit reason why I used Twitter4j. It was just one of many possibilities to gain some Twitter-Streams to demonstrate Flink’s Streaming-API capabilities. You could substitute any other streaming data source.
Regards,
Harris
I am reading it much later but it is an excellent blog by you, as usual.
Thanks, Nirmalya. 🙂
Hi Harris,
I am building a data pipeline wherein I have to show the twitter streaming data in kibana through Elastic search. At this point of time, my architecture is using Flume to get the data from Twitter Firehose API then Push it into Hive wherein I do Data cleaning and push the Data to Elastic search tables for kibana.
I have 2 questions.
1. Is it possible to replace this architecture with Flink?
2. Can Python be used in place of Java in the above coding?
TIA
Hi Gagandeep,
These are complex questions pointing at very different parts of the overall architecture. I think it’s best to post such questions on Flink/Python StackOverlow forums as there are many more experienced users who can give you more detailed information.
This is just a Blog 🙂
Kind regards,
Dear harris
Hope doing good!
Am new to flink and having doubts
My task is to convert the messages to JSON format by receiving messages from socket.
My perl program sending messages to a particular port through socket.
My objective is reads these perl streaming messages from flink and converting into JSON.
Question
1. is possible to read perl sterming data from flink?
Please find my below perl code to send messages
# create a connecting socket
use IO::Socket::INET;
my $socket = new IO::Socket::INET (
PeerHost => ‘127.0.0.1’,
PeerPort => ‘7777’,
Proto => ‘tcp’,
);
die “cannot connect to the server $!\n” unless $socket;
my $postm = sprintf ‘Test message’;
my $size = $socket->send($maxmsg);
$socket->close();
am receiving the message by running perl server.
Now i want to receive this message from Apache Flink to process , am totally new to flink , please guide
Please help me in this regards.
I have this problem too. Would you please tell me if you solved your issue?
Many thanks.