17 minutes read
I’ve already mentioned Apache Spark and my irrational plan to integrate it somehow with this series but unfortunately the previous articles were a complete mess so it has had to be postponed. And now, finally, this blog entry is completely dedicated to Apache Spark with examples in Scala and Python.
The notebook for this article can be found here.
Apache Spark Definition
By its own definition Spark is a fast, general engine for large-scale data processing. Well, someone would say: but we already have Hadoop, so why should we use Spark? Such a question I’d answer with a remark that Hadoop is EJB reinvented and that we need something more flexible, more general, more expandable and…much faster than MapReduce. Spark handles both batch and streaming processing at a very fast rate. Compared with Hadoop its in-memory tasks run 100 times faster and 10 times faster on disk. One of the weak points in Hadoop’s infrastructure is the delivery of new data, for example in real-time analysis. We live in times where the 90% of word’s current data was generated in the last two years so we surely can’t wait for too long. And we also want to quickly become productive, in a programming language we prefer, without writing economically worthless ceremonial code. Just look at Hadoop’s Map/Reduce definitions and you’ll know what I’m talking about.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
Here’s an example in Python which we’ll later use in Jupyter:
moby_dick_rdd.flatMap(lambda line: line.split(” “)).map(lambda word: (word, 1)).reduceByKey(lambda x,y: x + y)
But a few things remain the same: the underlying Filesystem, HDFS, is not going away because Spark is only a processing Engine and doesn’t dictate what your distributed Filesystems have to be. Spark is compatible with Hadoop so you don’t have to create everything from scratch when transferring your old MapReduce logic to Spark’s ecosystem. The same applies to your YARN scheduler and Mesos cluster manager. Spark brings its own Scheduler too: Standalone Scheduler.
Spark Architecture
If you look at Spark’s architecture you’ll recognize that there’s a core component which lays the foundation for hosting a very diverse set of functionalities:
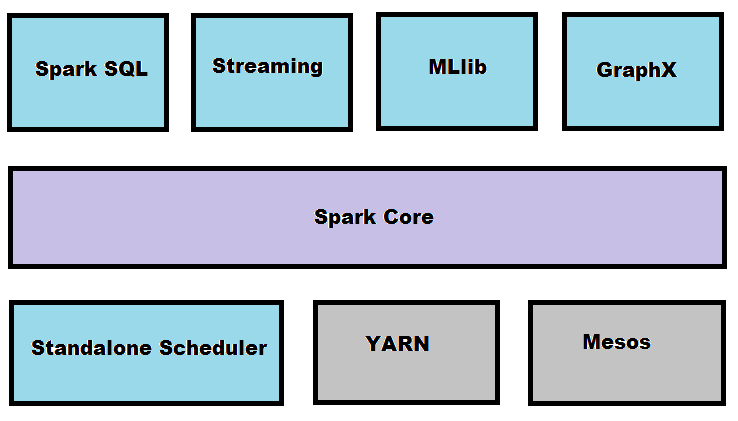
Spark Core covers the basic functionality like scheduling, fault recovery, memory management, interactions with the storage system. And as we’ll later see in this article here’s is the place where the most important abstraction, RDD (resilient distributed dataset) is defined as well as the APIs to work with them.
Spark SQL replaces the previous API for accessing structured data, Shark. It supports queries via SQL and Apache HQL (Hive Query Language). This API allows accessing different types of structured data storages like databases, JSON files, Parquet, Hive Tables etc.
Spark Streaming is the engine for processing of live data streams. It’s functionality is similar to Apache Storm. It can consume data from Twitter, HDFS, Apache Kafka and ZeroMQ.
MLlib is a library designed for doing machine learning tasks. It comes with different ML algorithms like classification, regression, clustering, filtering etc.
GraphX is a library for processing and manipulating graphs. For example Facebook’s “friends”, Twitter “followers” etc. It comes with a set of specialized algorithms for processing such data, like PageRank, triangle counting, label propagation etc.)
Spark Definition
For our purposes we define Spark as a distributed execution environment for large-scale computations. Spark itself is built with Scala and runs on JVM but supports different languages and environments. It also contains a nice web-interface to control the status of distributed tasks. Here we see a screenshot showing the status of a Python job. Later we’ll learn how to use Spark with Jupyter.

Resilient Distributed Data sets
Take almost any written Spark tutorial or video and sooner or later you’ll approach RDDs. This TLA (three-letter-acronym) describes the building block of Spark’s architecture and is all you need to know to be able to use any of the aforementioned functionalities. RDDs are immutable distributed collections of objects. With “objects” we mean anything you can use (documents, videos, sounds, blobs,…whatever). They’re immutable because an RDD can’t be changed once it has been created. It’s distributed because Spark splits RDDs into many smaller parts which can be distributed and computed over many different computing nodes. Simply imagine you have a cluster comprising 20 machines and now you want to do some Natural Language Processing on a very big chunk of scientific articles. Spark would take this “blob”, create an RDD out of it and split it internally into many smaller parts and send them to all available nodes over the network. The next time you start a computation on this RDD (because all you see is still a single object) Spark would use your NLP-logic and send it to each and every participating node to do some computation on the part of the original data. After all of them have produced their partial computations you’d receive one final result. This is the very reason why RDDs have to be immutable and, of course, distributed. They must be immutable so that no manipulation of smaller parts can happen and they have to be distributed because we’re interested in fast calculations done in parallel over many nodes. To create an RDD we can use different programming languages, like Scala, Java, Python or R. In this article we’ll use both Scala and Python to create a Spark Context, configure it and load some text to play with it for a bit. But before we can use Spark we have to configure it. Here we’ll use it as a single-instance, for testing purposes. In “real world” you’d usually have a master instance controlling other nodes.
Installing and Configuring Apache Spark
- I’m using Windows and there are some additional steps during the installation which I’ll explain as we proceed. First, go to Apache Spark homepage and download v.1.5.1 pre-built for Hadoop 2.6 an later.
- Unpack the tarball (under Windows you have to use an packer like 7zip because Windows doesn’t recognize tarballs)
- Apache Spark doesn’t contain a precompiled version of Hadoop for Windows. Therefore you have to build it yourself. Or download a precompiled version 2.6 from here.
- Insert new environment Variables HADOOP_HOME and HADOOP_CONF_DIR pointing to the root of your Hadoop install-dir respective config-dir within your Hadoop’s root. This is how it looks on my machine:

- Also insert SPARK_HOME pointing to the root-dir of your Spark installation.
- Spark is built with Scala and runs on JVM, therefore we need Scala and JVM installed on our machines. Additionally we install Scala’s Simple Build Tool SBT.
Using Apache Spark from Command Line
To start Spark we simply use a shell-script from its bin-directory. Type in spark-shell and soon a bunch of messages will start to flow in.

After a few seconds you’ll see a prompt like this:
A scala-based REPL (read-evaluate-print-loop) is awaiting commands. A default SparkContext is available through the variable sc. Just type in sc. and press TAB to expand all its properties and methods.

We’ll now use the SparkContext to read a text file and put it into a new variable, or to be more scala-ish: into a val. In Scala there’s a difference between mutable variables declared with keyword var and immutable “variables” declared with val (the “val” stands for value which implies immutability)

We see a lot of messages which are not only related to reading a file. There are “ensureFreeSpace” calls, broadcasts, some “pieces” were mentioned etc. At the very end of the stream we get the message that an RDD has been created and its name is moby_dick. Well done! This is our first RDD. RDDs are named by its origin: ScalaRDDs, PythonRDDs etc.
Now let’s see what the Spark WebConsole says about it. Go to your https://localhost:4040 and search for a textFile-Job (then name of the job could differ on your machine)
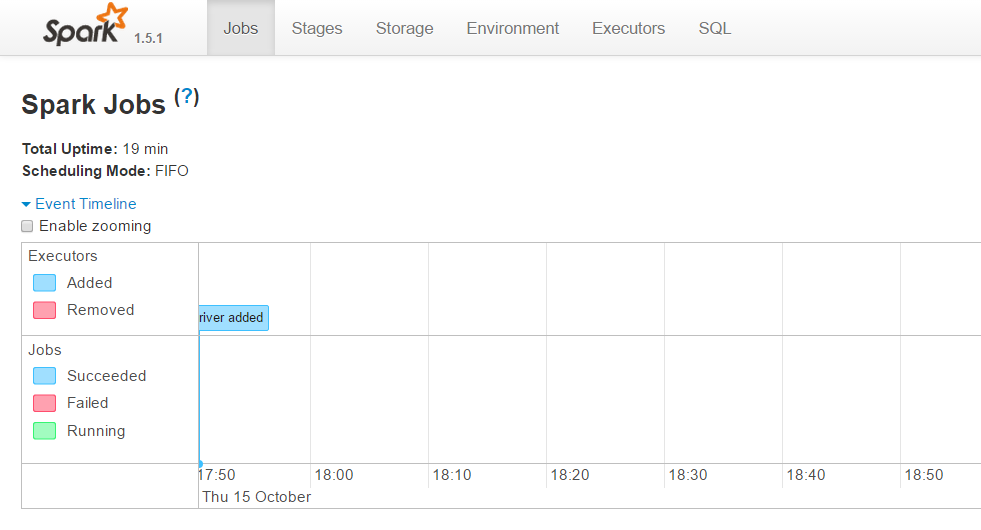
Um, well, there are no jobs at all! Am I kidding you? Yes, I do! But for your own good. Trust me, because Apache Spark is lazy! Spark is simply doing nothing because there’s no reason to read this file. But why? How can Spark decide when and what to do with some piece of data?
OK, just imagine we’re not reading Herman Melville’s Moby Dick but some extremely large text corpus. For example, gigabytes of Log-Files provided by Apache Kafka which you want to analyze line by line. So, you give Spark this log-file’s path and then…it blocks everything because it’s reading it as a whole….and reading it….and….you wait….and your memory goes down…and there’s even less memory available for your filtering logic…and you still have to wait….OutOfMemoryException...well, that’s not nice!
Apache Spark is not only lazy but it also offers two types of operations to work with RDDs: transformations and actions. Transformations are operations that construct new data from previous data. There is no change of original data as we already know because RDDs are immutable. This is nothing new to you if you call yourself a “functional programmer”, or simply love Haskell and laugh at other coder’s problems with shared mutable state. But I’m not going to annoy you with my superficial knowledge about Category Theory, Monoids & Monads. 
An action in Spark is technically a computation which produces a value which can either be returned to the caller (the driver program) or persisted into an external storage. When Spark executes an action some computation will be executed and a data type is returned but not an RDD. When a transformation “happens” an RDD will be returned but no computation kicked off or any kind of other data type generated.
In our example above nothing has happened because there was no action in sight. Let’s add a simple foreach action which will go over all words of Moby Dick and print them out in the console. Prepare yourself for a quick stream of unreadable data and also check the output in the WebConsole while the job is being executed.

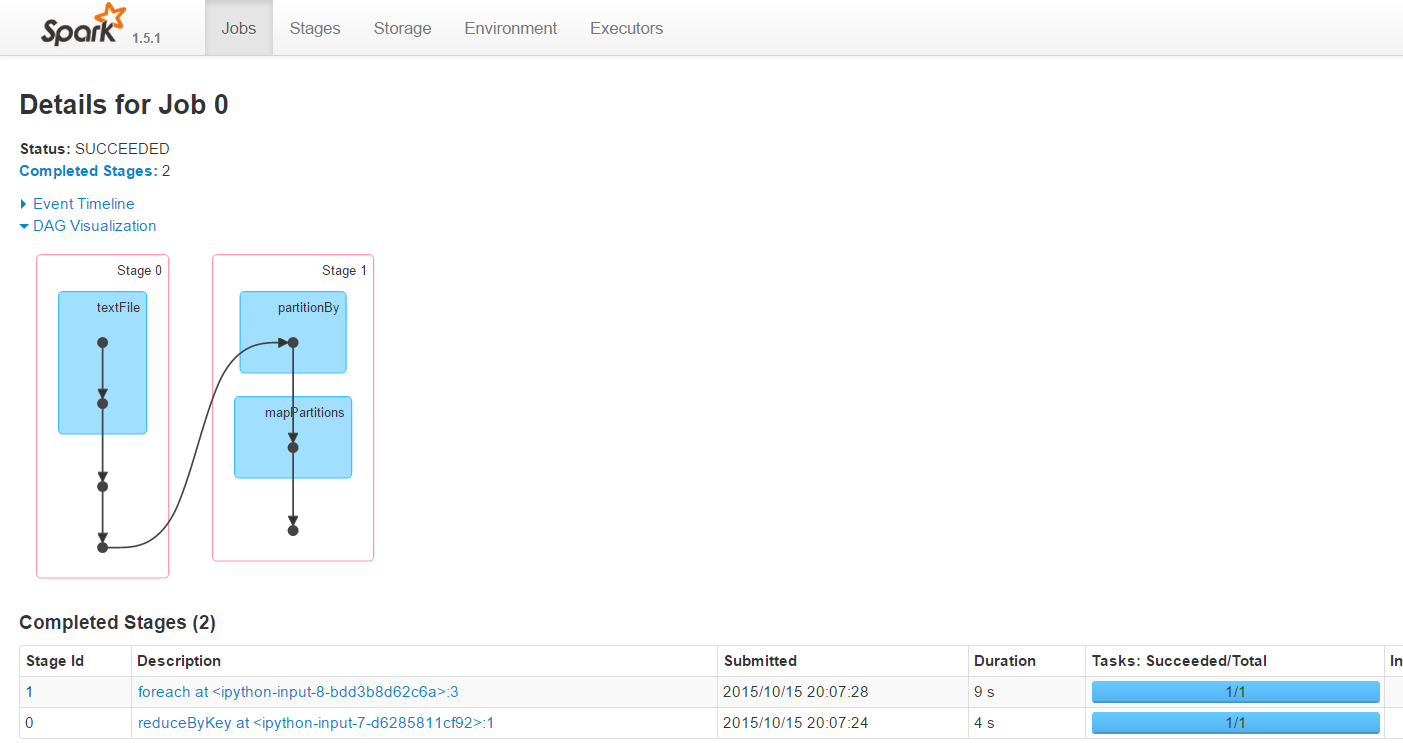
Our WebConsole now shows a completed job and its metadata:
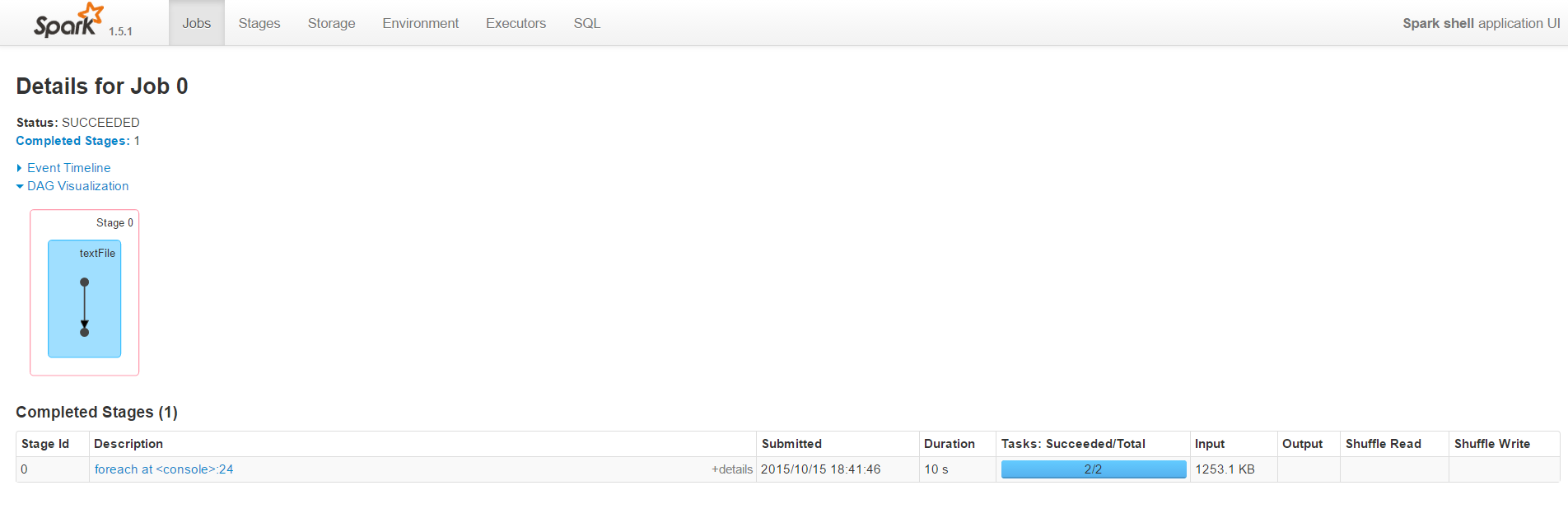
If you click on the small dots in the visualization box you’ll get a more detailed information about different stages of the job.
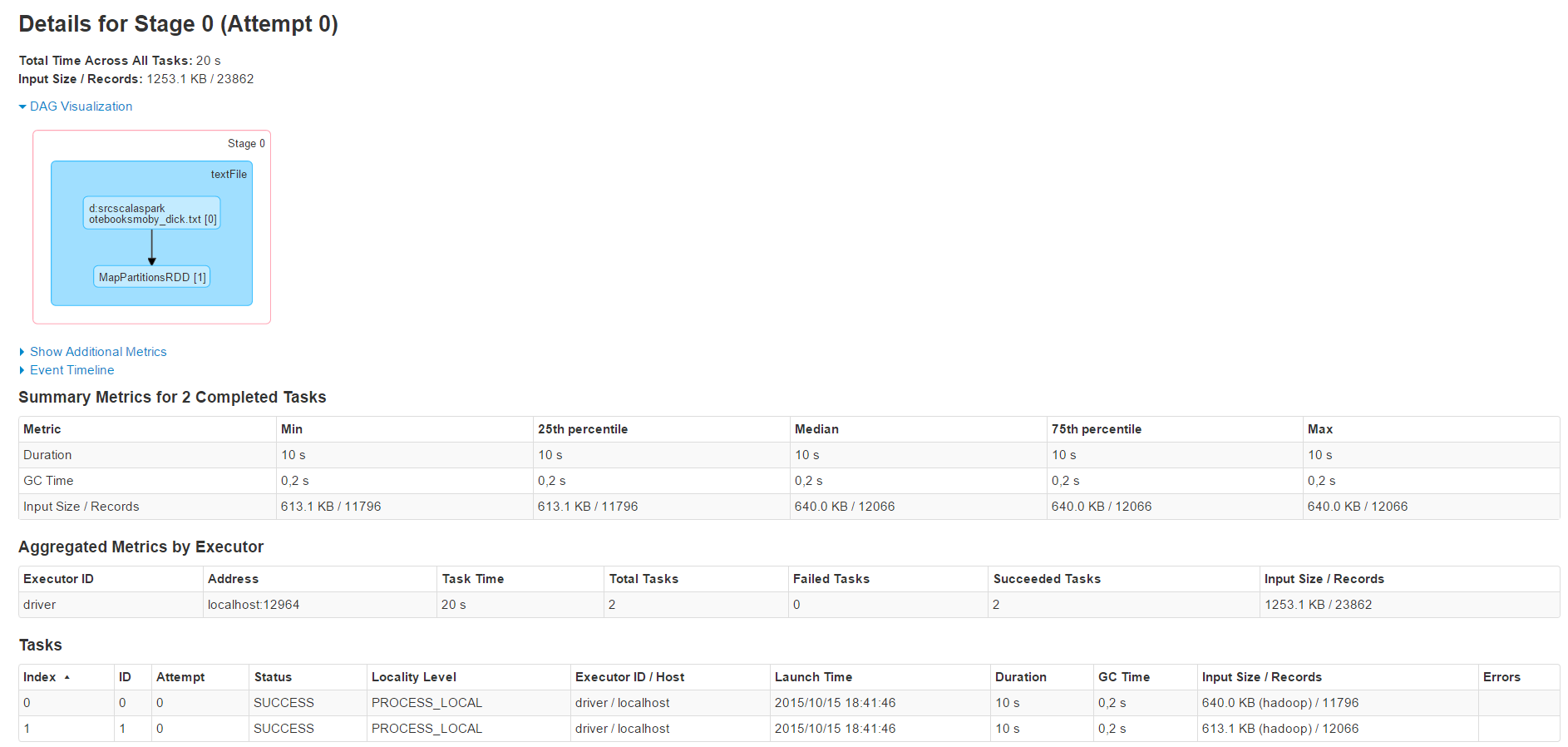
Here you can see the different tasks belonging to the job, their localities (which of your nodes executed them), memory consumption and if they were successful or not. Because we’re using a single-node Spark instance all these values are not of much value to us but imagine processing large chunks of data on a cluster. Then you have to have such detailed information.
Caching Data in Apache Spark
Data doesn’t have to be located on persistent storages only. You can also cache it in memory and Spark will provide you all the tools needed to advance your processing logic. We can instruct Spark to cache data by using the cache method of the RDD.

If we now go to our WebConsole and click the Storage-Link we’d see…well, I assume you already knew it: there’ll be nothing waiting for us. Why? The answer is simple: because a cache method is a Transformation (and it’s a transformation because it returns an RDD), so nothing will be executed by Spark unless we call some action on it. The principle is simple: when I have to return an RDD then I’m a transformation and because I’m a transformation I simply do nothing because I’m lazy. If I return something that’s not an RDD then I’m an action. And because I’m an action I’m everything else but not lazy. This is the mantra of Apache Spark.
Now let’s split all the words by white space so we can count all the words in Moby Dick. Again, we do a transformation first (flatMap) and then we execute the count-Action.
![]()
We let Spark count the words for us…this is the moment when everything kicks in…caching the RDD, splitting into single words, and counting them.
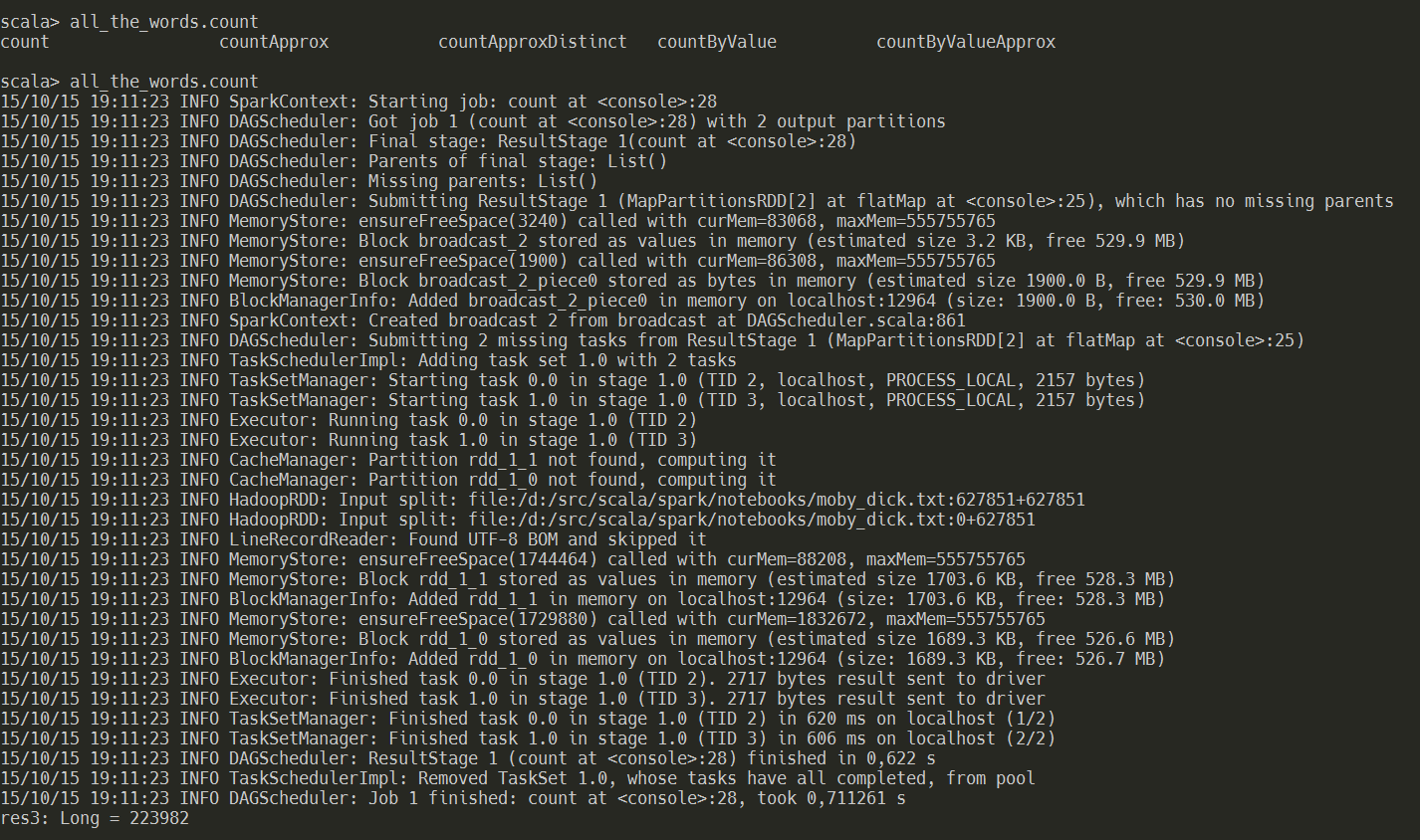
When we now check the Storage information in the WebConsole the page output looks differently:

Especially, the second table is interesting. There we encounter a new term: Partitions. What are partitions? Partitions are essentially physical parts of your original “documents” distributed over the nodes belonging to your Spark instance. An RDD is a logical representation of an entity that is physically separated and replicated over different machines. You don’t work with partitions because Spark uses them for management purposes only. What you see are RDDs only, and also DataFrames which represent a newer, and more sophisticated API to manage data under Spark. But in this article we’ll only use RDDs. Maybe in some following post we’ll also talk about DataFrames because they map perfectly with Pandas and R’s DataFrames. The most important difference between Spark’s and “other” DataFrames is the way of execution which is lazy in Spark’s context. Python and R eagerly load their DataFrames which is.
What you should also know is that for Spark an RDD is just an object without any additional, more special information. An RDD has to be maximally general and therefore it’s not always very “pleasant” to work with them. Usually problem domains influence the usage of tools and prescribe at least in part what kind of data has to be used, how their structure should look like, the way we query the data etc. In the field of Data Analysis people often deal with more or less structured data like Tables, Matrices, Pivots etc. And this is the reason why using DataFrames in Spark is much more productive that fiddling around with raw RDDs because they come preformatted as columnar structures ready to be queried like any other data storage by using well-known methods.
Connecting with Apache Spark from Jupyter
The examples above are based on Scala, a language I didn’t introduce properly which is everything but not “nice”. However, as this article series will (hopefully) be continued I’ll try to find a few spots to give a few examples on Scala. I’m not sure how interesting a mini-tutorial on Scala would be (or if these articles are in any way useful to anyone) but, being a Loser’s article series, one can only expect a chaotic structure, misleading examples and obviously incomplete explanations. 😳
However, let’s see how the Python Shell communicates with Apache Spark? The easiest way to do this is just by executing another shell-script from Spark’s bin-directory: pyspark. This would bring us a command prompt similar to the one from Scala.
Here we could execute our Python code directly and play the same game as with Scala. But the title of this paragraph contained the term Jupyter and Jupyter is not a console-only tool. So, how to communicate with Spark via Jupyter? Actually, there are many different ways and I’ve found some kernels with complete environments dedicated to Spark but there are also different requirements regarding Jupyter versions (some want only 3.0, others want IPython only and not Jupyter etc.). Therefore I’ll show the simplest and surely the most primitive method to create a SparkContext and send it Python commands from Jupyter.
- Put the full path to the py4j package into your PYTHONPATH. py4j is located under your Spark’s python-dir.
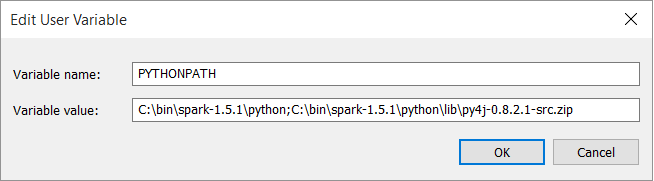
- Then execute the jupyter notebook command from your notebook’s directory (I use Jupyter v4.0)
- Import SparkConf and SparkContext from pyspark
- Create a new “local” SparkConf and give it a name
- Instantiate a new SparkContext by giving it this “local” config
- After executing the above command you’ll see a bunch of messages flowing into your console
- Now you can send commands to the new SparkContext-instance
The console output shows Spark logs after the context has been initialized:
Now we can send commands to our new Spark instance:
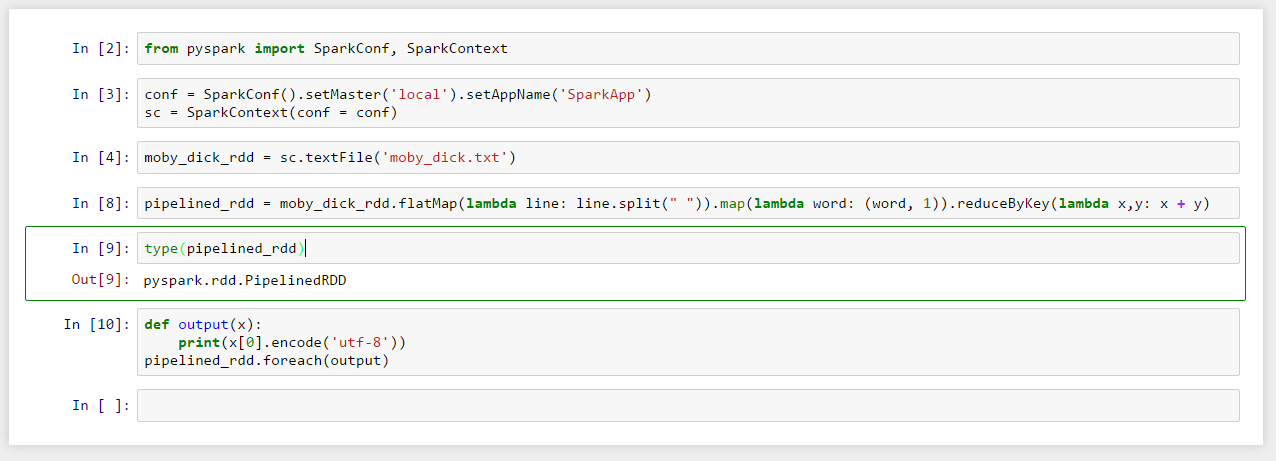
Here we’re using the textFile-Transformation to create a new RDD which we’ll send through our transformation pipeline:
- Create a flatMap consisting of all words from the book separated by white space
- map these words to tuples consisting of word-names and a value of 1
- Use reduceByKey on all tuples to create unique word groups by accumulating their numeric values (simply spoken: count & group words)
- And finally, the foreach-action triggers some visible “action” by applying the function output to each element in the list of tuples.

The corresponding job information will show up in the Spark WebConsole:
Conclusion
I hope this article could explain a few parts of the Apache Spark structure and its abstractions. There’s, of course, much much more to be explained and I didn’t even touch any of the components (Spark SQL, Streaming, MLlib etc.). Maybe in some later article because I want to dedicate the next article to scikit-learn and the general Machine Learning concepts. But after we’ve learned a bit about ML we surely could use a bit of Apache Spark to execute some nice ML-code. What do you think about? Just leave a comment. Thank you. 🙂
Regards,
Harris

{kind=link}
{kind=link}
{kind=link}
{kind=link}
8 thoughts on “Data Science for Losers, Part 3 – Scala & Apache Spark”
Hello sir I have done every step you written in your bole to run apache spark within jupyter notebook. I have installed latest anaconda and update conda then I downloaded spark 1.5.1 and set SPARK_HOME envoirnment variable and then download pre compiled version of hadoon ans set HADOOP_HOME= C:\Users\InAm-Ur-Rehman\hadoop-2.6.0\bin\hadoop and HADOOP_CONF_DIR=C:\Users\InAm-Ur-Rehman\hadoop-2.6.0\etc\hadoop and then I installed scala JRE and SBT as you said and then I set PYTHONPATH=C:\Users\InAm-Ur-Rehman\spark-1.5.1-bin-hadoop2.6\python\lib\py4j-0.8.2.1-src. and started my notebook using this command jupyter notebook. but when I write this from pyspark import SparkConf, SparkContext it says ImportError: No module named ‘pyspark’ what am i missing?
Hi Inam,
Your PYTHONPATH should contain the py4j-Library _and_ the Python binary from the Spark directory.
Here’s the link to the screenshot from the above article: http://blog.brakmic.com/wp-content/uploads/2015/10/py4j.png
Thanks alot sir..this works. but there is another issue. I want to use spark DataFrames in notebook. I tried to define sparkcontext sc and hive context as sqlcontext using your given script this
spark_home = os.environ.get(‘SPARK_HOME’, None)
sys.path.insert(0, spark_home + “/python”)
# Add the py4j to the path
sys.path.insert(0, os.path.join(spark_home, ‘python/lib/py4j-0.8.2.1-src.zip’))
# Initialize PySpark to predefine the SparkContext variable ‘sc’
execfile(os.path.join(spark_home, ‘python/pyspark/shell.py’))
it gives me error NameError: name ‘execfile’ is not defined whats the problem? I want to load csv file in notebook and do some analysis no it.
I don’t know much about your local machine/path settings so you’d have to google around. Here’s one possible solution to your problem: http://stackoverflow.com/questions/29783520/create-pyspark-profile-for-ipython
Kind regards,
Ok sir thanks for your time. I’ll search for a solution. its a wonderful blog for a losers like me.
Hello Sir I managed to start notebook with sc defined. I am trying to load csv file into notebook using this code
CV_data = sqlContext.read.load(‘./data/churn-bigml-80.csv’,
format=’com.databricks.spark.csv’,
header=’true’,
inferSchema=’true’)
final_test_data = sqlContext.read.load(‘./data/churn-bigml-20.csv’,
format=’com.databricks.spark.csv’,
header=’true’,
inferSchema=’true’)
CV_data.cache()
CV_data.printSchema()
It gives error Py4JJavaError: An error occurred while calling None.org.apache.spark.sql.hive.HiveContext.
and Exception: (“You must build Spark with Hive. Export ‘SPARK_HIVE=true’ and run build/sbt assembly”, Py4JJavaError(‘An error occurred while calling None.org.apache.spark.sql.hive.HiveContext.\n’, JavaObject id=o20))
what should I do to resolve this? can you help?
This is related to Apache Hive so you’ll have to consult their docs. Or just google around, for example at StackOverlow.
Ok sir thanks