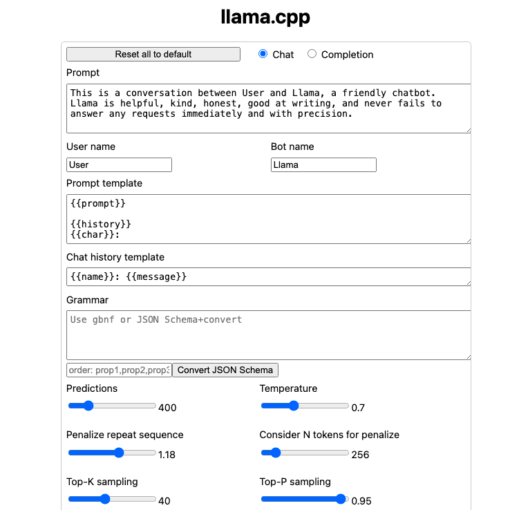
Learn how to extend Llamafile with LangChain’s JsonParser to produce clean, structured JSON output
Python
11 posts

This article offers a personal look at a C++ library implementing PKCE with Keycloak. It’s intended more as a learning exercise than a production-ready solution. You’ll find a C wrapper and additional Python and Lua wrappers, plus a quick rundown on PKCE fundamentals, library structure, and example demos.

Discover the innovative world of Bosque, a programming language developed by Microsoft Research that champions the regularized programming paradigm. In this post, I explore the key advantages of Bosque, such as immutable state and intent-focused coding, and share my journey integrating it into JupyterLab. Learn how I developed custom kernels in Python and crafted syntax highlighting extensions using TypeScript and Lezer parsers. Whether you’re intrigued by Bosque’s approach or looking to enhance your JupyterLab environment, this article provides valuable insights and practical guidance to help you get started. Dive in to see how Bosque can transform your programming experience and streamline your development workflow!

In this article we’ll explore Microsoft’s Azure Machine Learning environment and how to combine Cloud technologies with Python and Jupyter. As you may know I’ve been extensively using them throughout this article series so I have a strong opinion on how a Data Science-friendly environment should look like. Of course, there’s nothing against other coding environments or languages, for example R, so your opinion may greatly differ from mine and this is fine. Also AzureML offers a very good R-support! So, feel free to adapt everything from this article to your needs. And before we begin, a few words about how I came […]

Sometimes, the hardest part in writing is completing the very first sentence. I began to write the “Loser’s articles” because I wanted to learn a few bits on Data Science, Machine Learning, Spark, Flink etc., but as the time passed by the whole degenerated into a really chaotic mess. This may be a “creative” chaos but still it’s a way too messy to make any sense to me. I’ve got a few positive comments and also a lot of nice tweets, but quality is not a question of comments or individual twitter-frequency. Do these texts properly describe “Data Science”, or at […]
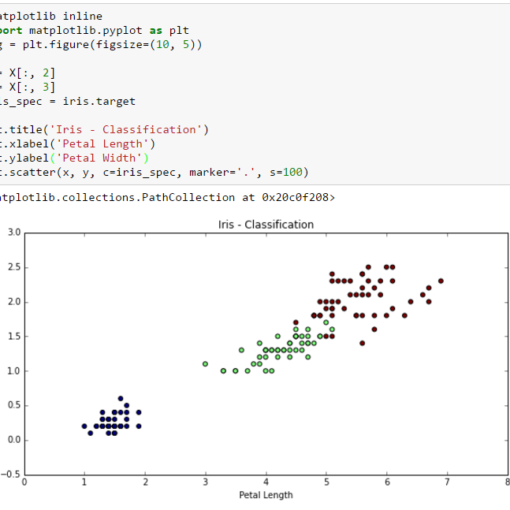
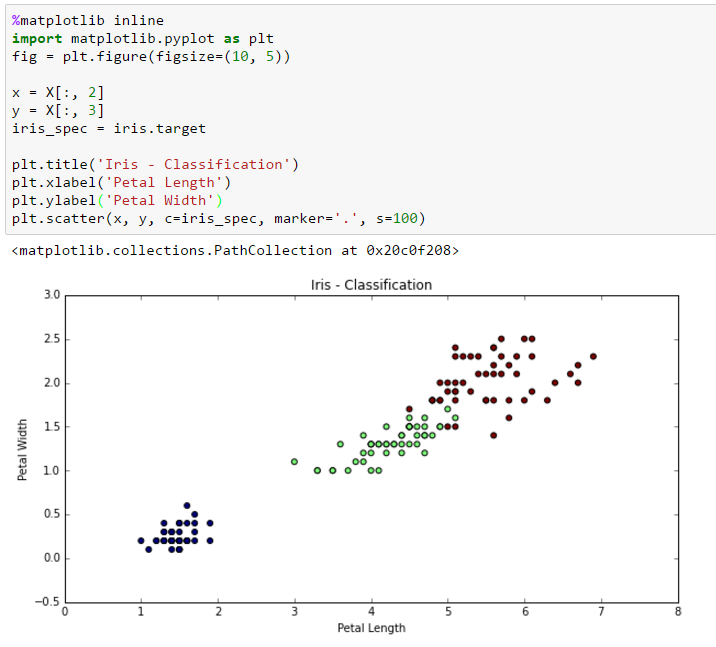
It’s been a while since I’ve written an article on Data Science for Losers. A big Sorry to my readers. But I don’t think that many people are reading this blog. Now let’s continue our journey with the next step: Machine Learning. As always the examples will be written in Python and the Jupyter Notebook can be found here. The ML library I’m using is the well-known scikit-learn. What’s Machine Learning From my non-scientist perspective I’d define ML as a subset of the Artificial Intelligence research which develops self-learning (or self-improving?) algorithms that try to gain knowledge from data and make predictions […]
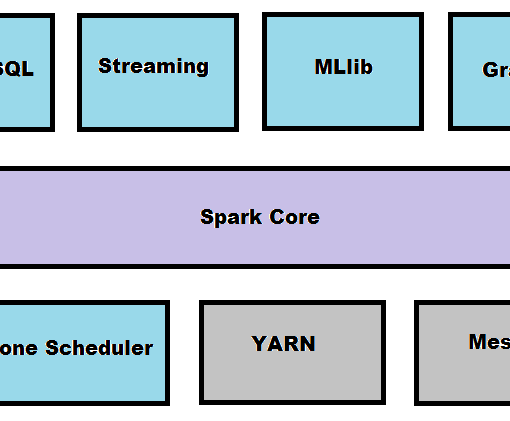
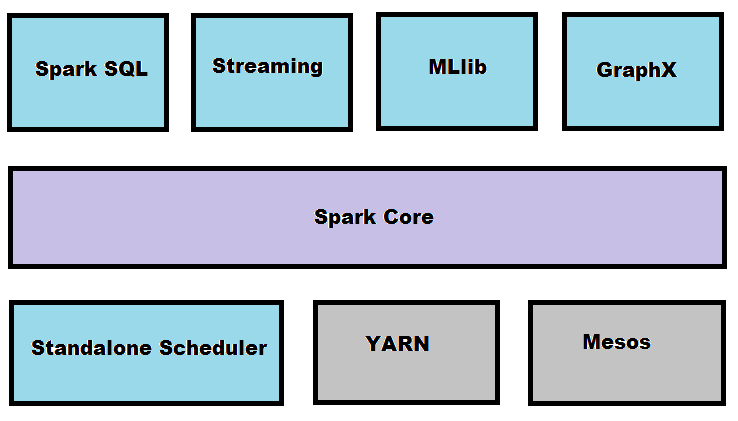
I’ve already mentioned Apache Spark and my irrational plan to integrate it somehow with this series but unfortunately the previous articles were a complete mess so it has had to be postponed. And now, finally, this blog entry is completely dedicated to Apache Spark with examples in Scala and Python. The notebook for this article can be found here. Apache Spark Definition By its own definition Spark is a fast, general engine for large-scale data processing. Well, someone would say: but we already have Hadoop, so why should we use Spark? Such a question I’d answer with a remark that Hadoop is EJB reinvented and […]

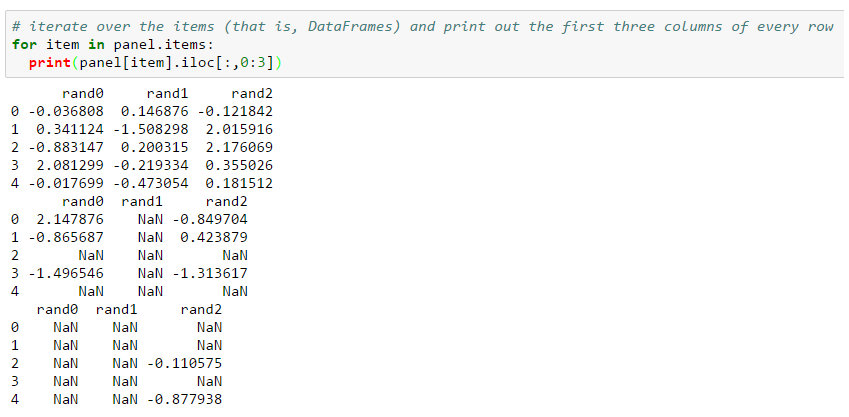
This should have been the third part of the Loser’s article series but as you may know I’m trying very hard to keep the overall quality as low as possible. This, of course, implies missing parts, misleading explanations, irrational examples and an awkward English syntax (it’s actually German syntax covered by English-like semantics 😳 ). And that’s why we now have to go through this addendum and not the real Part Three about using Apache Spark with IPython. The notebook can be found here. So, let’s talk about a few features from Pandas I’ve forgot to mention in the last two articles. Playing SQL with DataFrames Pandas is wonderful because of […]

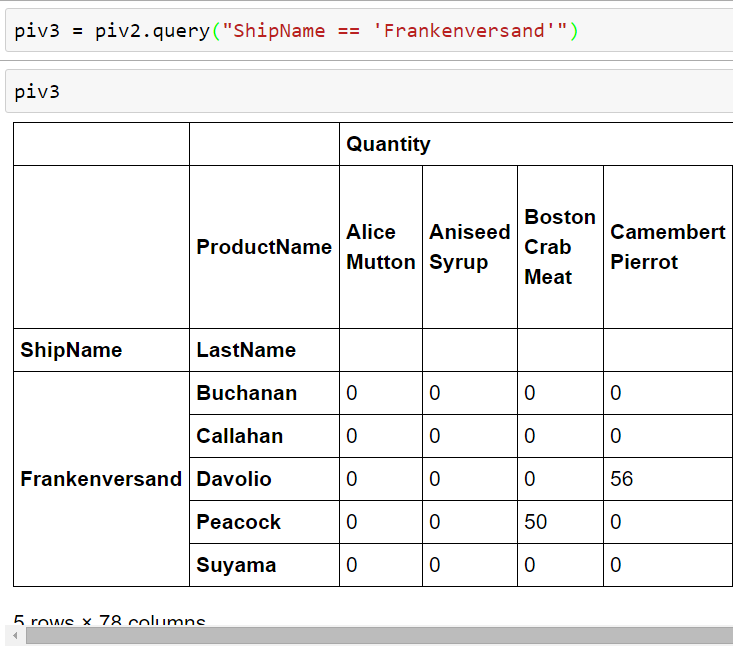
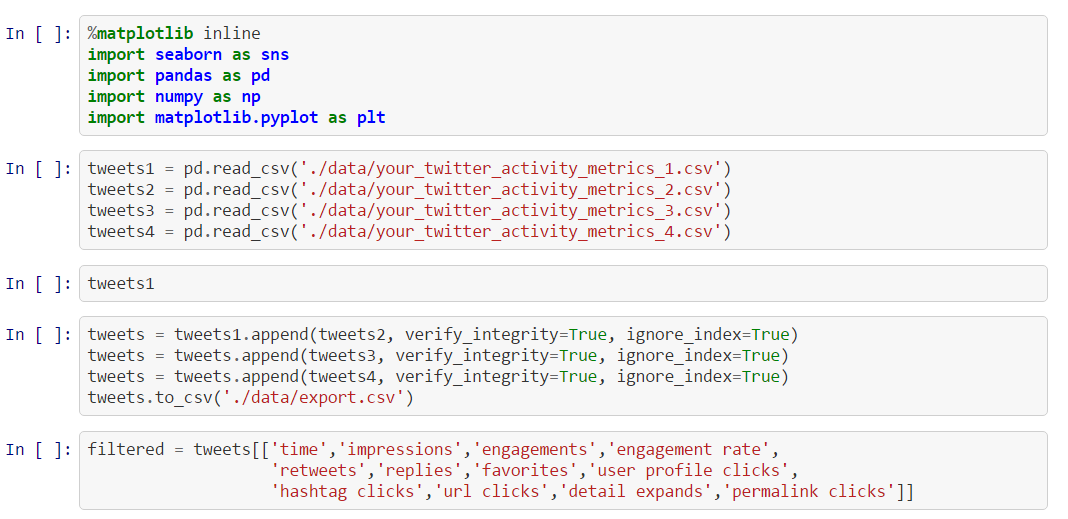
In the first article we’ve learned a bit about Data Science for Losers. And the most important message, in my opinion, is that patterns are everywhere but many of them can’t be immediately recognized. This is one of the reasons why we’re digging deep holes in our databases, data warehouses, and other silos. In this article we’ll use a few more methods from Pandas’ DataFrames and generate plots. We’ll also create pivot tables and query an MS SQL database via ODBC. SqlAlchemy will be our helper in this case and we’ll see that even Losers like us can easily merge and filter SQL tables without touching the […]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Anaconda Installation To do some serious statistics with Python one should use a proper distribution like the one provided by Continuum Analytics. Of course, a manual installation of all the needed packages (Pandas, NumPy, Matplotlib etc.) is possible but beware the complexities and convoluted package dependencies. In this article we’ll use the Anaconda Distribution. The installation under Windows is straightforward but avoid the usage of multiple Python installations (for example, Python3 and Python2 in parallel). It’s best to let Anaconda’s Python binary be your standard Python interpreter. Also, after the installation you should run these commands: conda update conda conda update “conda” […]