
{kind=link}
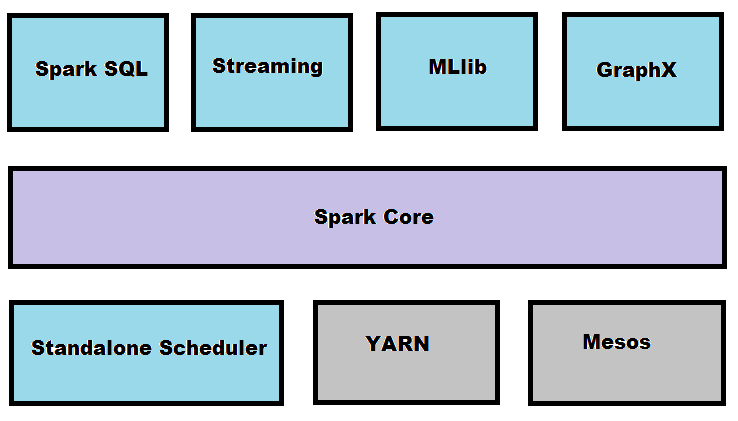
I’ve already mentioned Apache Spark and my irrational plan to integrate it somehow with this series but unfortunately the previous articles were a complete mess so it has had to be postponed. And now, finally, this blog entry is completely dedicated to Apache Spark with examples in Scala and Python. The notebook for this article can be found here. Apache Spark Definition By its own definition Spark is a fast, general engine for large-scale data processing. Well, someone would say: but we already have Hadoop, so why should we use Spark? Such a question I’d answer with a remark that Hadoop is EJB reinvented and […]
hadoop
1 post