
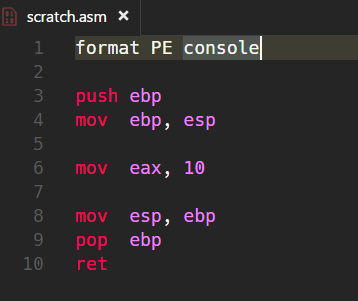
There are many good tutorials on this topic so I’m not trying to write the next ‘best’ intro to assembly under Windows. Rather, I’ll try to explain certain concepts which I’ve found to be hard to understand. In this first installment I aim to describe the Stack and how it works in concert with important registers EBP, ESP and EIP. Of course, before we explore this territory we’d first have to explain the meaning of registers and movements inside of computer’s memory. Therefore, let’s first build up a working infrastructure for editing of assembly code. PDF Version of this article. […]

In this article we’ll learn about Angular2 Services. Our example App will contain a simple Logon-Form connected to a background Authentication-Service. This Auth-Service utilizes some of the default Angular2 mechanisms like Http, Rx/Observables etc. to provide us the needed infrastructure. Here’s a working demo for live testing. As always, the code is located on GitHub. But before we begin let’s provide a proper definition of a Service in Angular 2. What is a Service? A Service is a class annotated with @Injectable that contains some logic which can be used by different parties in the application. An Injectable doesn’t come into existence […]
In this article we’ll learn how to use the successors of former Angular 1.x filters: Pipes. As most of us know from own experience the data our apps consume is usually available in various formats that don’t fit very well to our (internal) processes. Also there are situations where we want to check some values first before going any further. And it’s not a big secret that from user’s perspective working with data via complex forms and numerous input fields would quickly become very cumbersome without all those nice little helpers like text formatters, syntax checkers, numeric converters etc. In this […]
Two weeks ago I wrote the first article for this series and I think it ended up being a chaotic bag of words filled with a myriad of different topics, examples and way too many screenshots. This happens when you learn something completely new instead of doing some more creative stuff on a weekend. Therefore, I’ll now focus this article on @Input, @Output and EventEmitter from Angular 2 rc1. Less is more and I’m planning to talk about other Angular 2 parts in further articles. But to effectively learn how to use a framework is always a question of practice than everything else […]

It’s been a while since I wrote anything here. But this blog isn’t dead or in ‘maintenance mode’. I’m just coming back from the trenches of web development and, as always, things are getting messier every day. So many new frameworks and ‘very-cool-best-practices one should follow’. However, with or without JavaScript fatigue let’s do something new and learn a few bits about the upcoming Angular 2. And just to make a few things clear: I’m not an experienced Angular developer and everything I show and explain here is based on my 2-day experience with the current Beta (today’s my second day). […]

Some time ago I tried to learn Elm. And believe it or not, I failed to compile a simple Hello-World program. Later I figured out that some interfaces have changed between certain versions of Elm making my failure inevitable. Long story short: the tutorial I found on the net was outdated and I didn’t know it. Well, how could I know this? Or more precisely: if a change in the language can hit a beginner so hard will he/she be willing to continue? In my case I ended up with PureScript. Often I hear or read that PureScript is ‘harder’ to learn […]

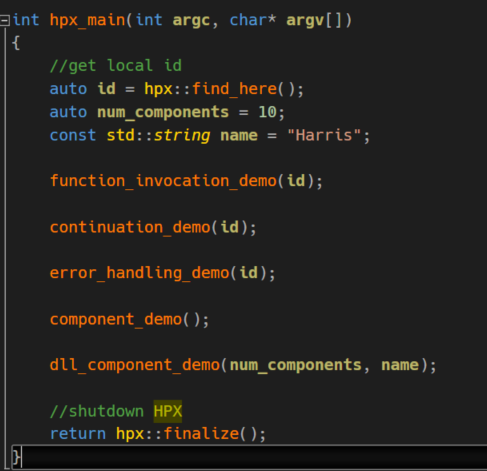
A few months ago I discovered a Project from Louisiana State University led by Prof. Kaiser that designs and develops a new execution model for future high performance architectures. It’s called ParalleX and its C++ implementation is named HPX (High Performance ParalleX). It supports operating systems like Linux or Windows and several Build-Toolchains (GNU, MSBuild, CMake etc.). In this article we’ll use Windows 10 x64 and Visual Studio 2015 to build up the base structure of HPX itself plus a small collection of demos showing some of the key aspects of it. The sources can be found here. Building HPX Before we can […]

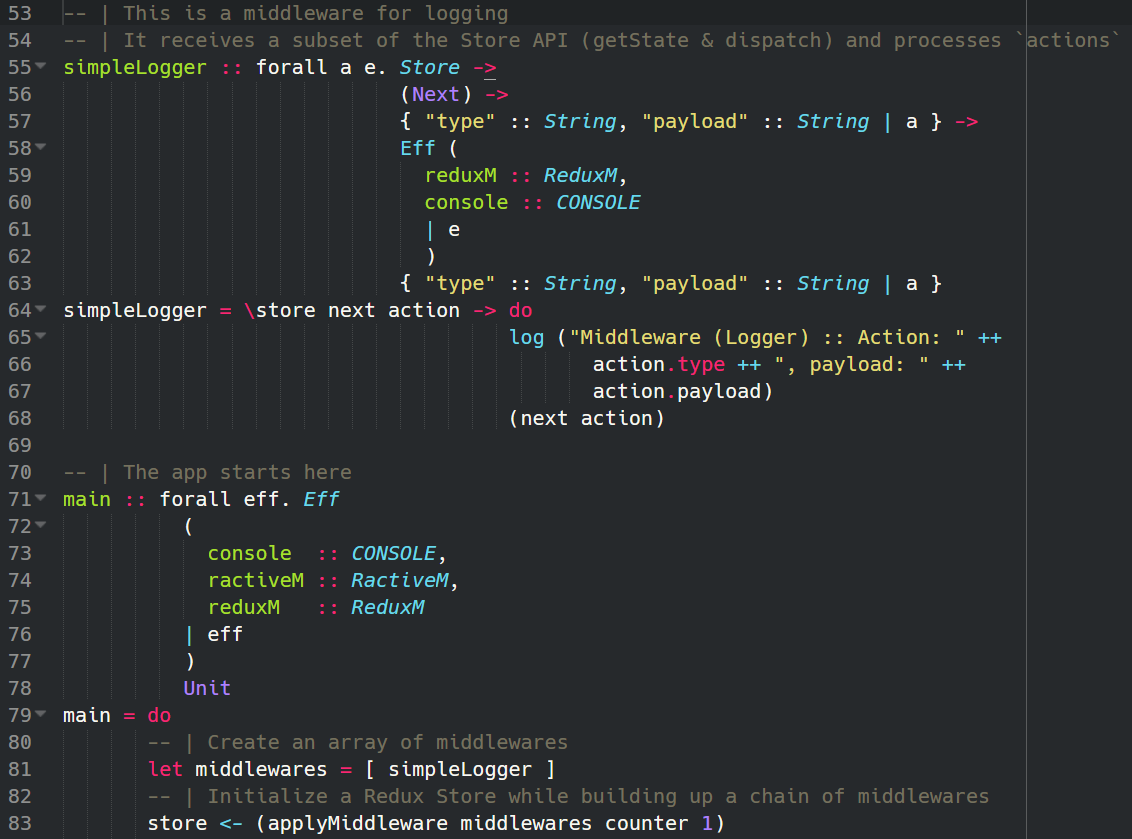
PureScript-Redux is a small library which helps to utilize the Redux state container with PureScript. Although I have almost no experience with React, which is the most prominent ecosystem for using Redux, I thought it would be a nice learning exercise to create a set of Redux-Bindings for writing WebApps in PureScript. Redux itself is heavily, and rightfully so, promoting the benefits of using pure functions for managing the application state and PureScript, being a Haskell-dialect, is a purely functional language. Therefore, it seemed to me very logical to try to combine them together. But because I’m also a PureScript-Beginner and still learning […]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
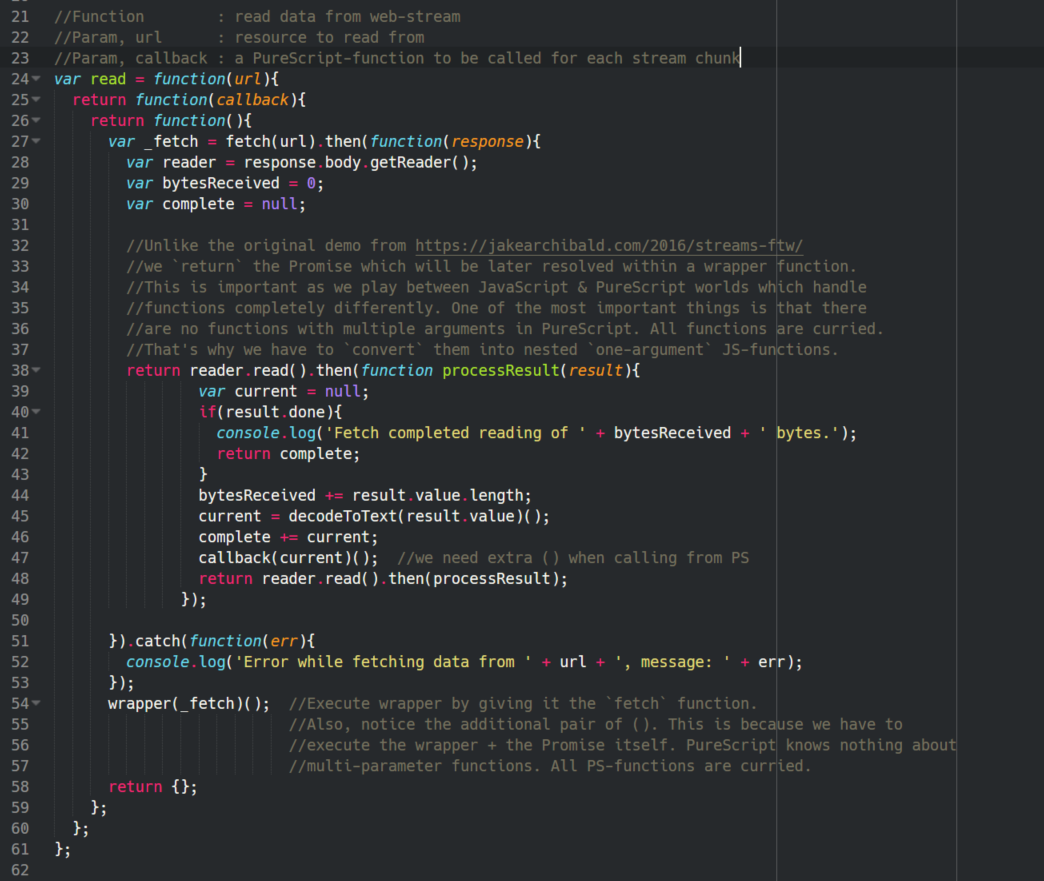
This is an updated version of the original article. I want to thank @joseanpg for the corrections and the idea regarding TextEncoder. Usually, my articles are mostly too long, filled with too many screenshots and philosophy. But this time I’ll try to remain concise and, hopefully, more precise than usual. I’ll refer to Jake Archibald’s article on Web Streams and his prediction that they’ll become the dominant web technology of the Year 2016 (in combination with Service Workers, of course). The article is filled with lots and lots of nice code examples you can basically copy & paste into your browser (some of […]
{kind=link}
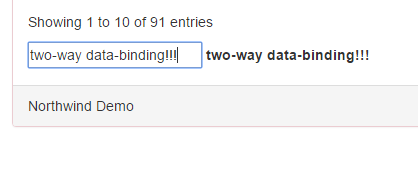
It’s been a while since I wrote my last article and. Actually, I planned to write the second part of my Scala Crash Course but in the mean time I adopted an orphaned (abandoned?) project called purescript-ractive that’s related to my favorite UI-Library, RactiveJS, and is written in a little, amazing language called PureScript. As many of you already know there are so many different languages that compile to JavaScript. There’s even a COBOL transpiler for JS! Therefore I’ll surely not waste your time discussing the (dis)advantages of Transpiling-to-JS vs. Writing-in-JS. Instead, I’ll try to describe the advantages of PureScript by explaining a small […]