6 minutes read
- Intro to Semantic Kernel – Part One
- Intro to Semantic Kernel – Part Two
- Intro to Semantic Kernel – Part Three
- Intro to Semantic Kernel – Part Four
- Intro to Semantic Kernel – Part Five
- Intro to Semantic Kernel – Addendum
In this segment, we delve into a crucial aspect of AI that often evokes a shiver down the spine: the notion of machines thinking autonomously, sifting through our data (including the private stash) at breakneck speed, orchestrating sinister plots from the shadows to subjugate humanity…just kidding! The jest probably didn’t tickle your funny bone, and perhaps I’ve lost some readers, rendering this blog a tad lonelier. Nonetheless, for the ardent souls still on board, let’s pivot to a significant pattern that’s gaining traction in the AI domain (or whatever nomenclature you prefer). We’re shedding light on the RAG pattern, shorthand for Retrieval Augmented Generation. I could meander through a plethora of papers and attempt a unique definition, but let’s slice through the jargon for a clean start. Essentially, RAG empowers your model to fetch data beyond the confines of its initial parameter set, addressing a common shortfall of Language Model Learning (LLM).
LLMs, by design, lean heavily on their parametric memory. The gargantuan parameter count, running into billions, bestows upon LLMs like ChatGPT, LlaMa, Falcon, and their ilk, an uncanny ability to churn out human-esque responses to our queries. However, this strength doubles as their Achilles’ heel since their knowledge reservoir is as deep as their parameter pool. Strip away the human-like facade, and an LLM boils down to a computation juggernaut, crunching numbers to predict the next sequence in a given prompt—essentially, a showcase of applied statistics. You might have encountered responses from ChatGPT, citing a “cutoff,” signaling a shortfall in current data, which either halts the engine or nudges it to conjure seemingly coherent, albeit baseless, answers—a phenomenon colloquially termed as “hallucination.” Although, I find the label a tad misleading as it hints at self-awareness, a trait starkly missing in LLMs. Only a thinking entity can hallucinate or grapple with psychological quandaries.
The RAG pattern emerges as a game-changer here, facilitating a bridge between your model and the external data realm, thus augmenting its response quality by grounding the generated content in real, updated data. This pattern could potentially be married with Semantic Kernel methodologies to enhance the interaction between the retrieval and generation phases, fostering a more nuanced, context-aware model output.
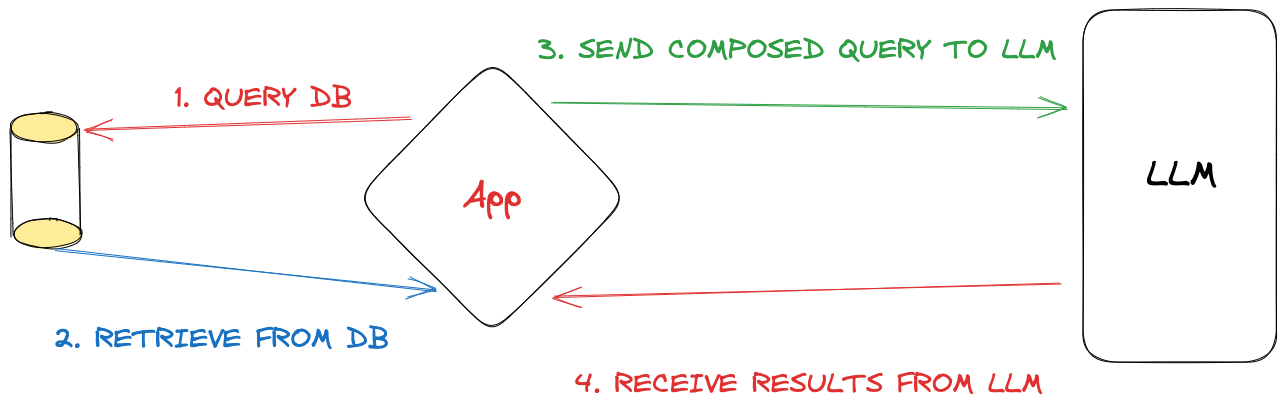
Here’s a typical RAG workflow in four steps:
- Query a database, which could be as basic as an SQL DB like SQLite or more advanced like vector databases such as Weaviate or Qdrant.
- Retrieve the database results.
- Merge the database findings with the LLM query, using the database results as the context.
- Obtain LLM results. With both its parametric memory and the added context, the LLM typically provides more accurate and less “hallucinatory” answers.
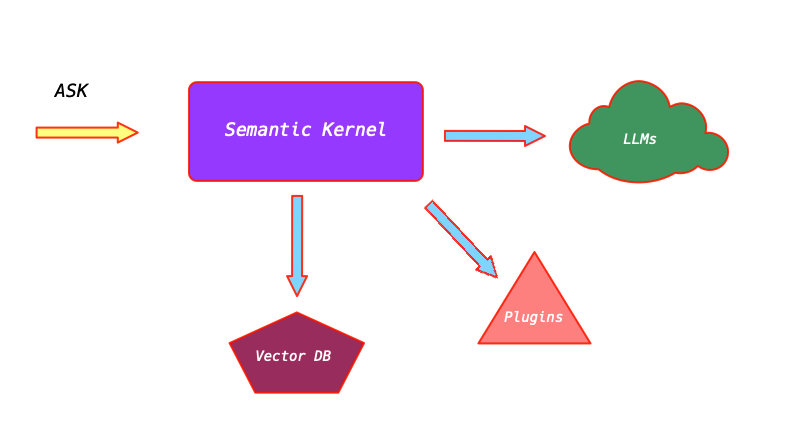
Integrating RAG with Semantic Kernel
Implementing the RAG pattern requires a more comprehensive kernel configuration, as illustrated below:
Next, we need to set up the MemoryStore. Several options are available, with a few highlighted here:
For this demonstration, I’m using SQLite, which is ideal for local development. However, for a more robust setup, you might consider vector databases like Weaviate or Qdrant. You can find further details in the “docker” subfolder of this article’s repository. After setting up the database, we need to define the embedding generator. For this example, we’ll use OpenAI’s embedding service.
We then merge the embedding generator with the memory store to form a semantic text memory, as demonstrated below:
As illustrated, there’s also a direct instantiation method for SemanticTextMemory. We then use the TextMemoryPlugin, passing in the SemanticTextMemory, to implement the Save and Recall functions, essential for managing our semantic text memory.
Subsequently, we populate the database with facts about an individual. This will vary based on your specific use-case, so adapt as needed. In the picture below, you can see the SQLite table containing our data and its corresponding embeddings.
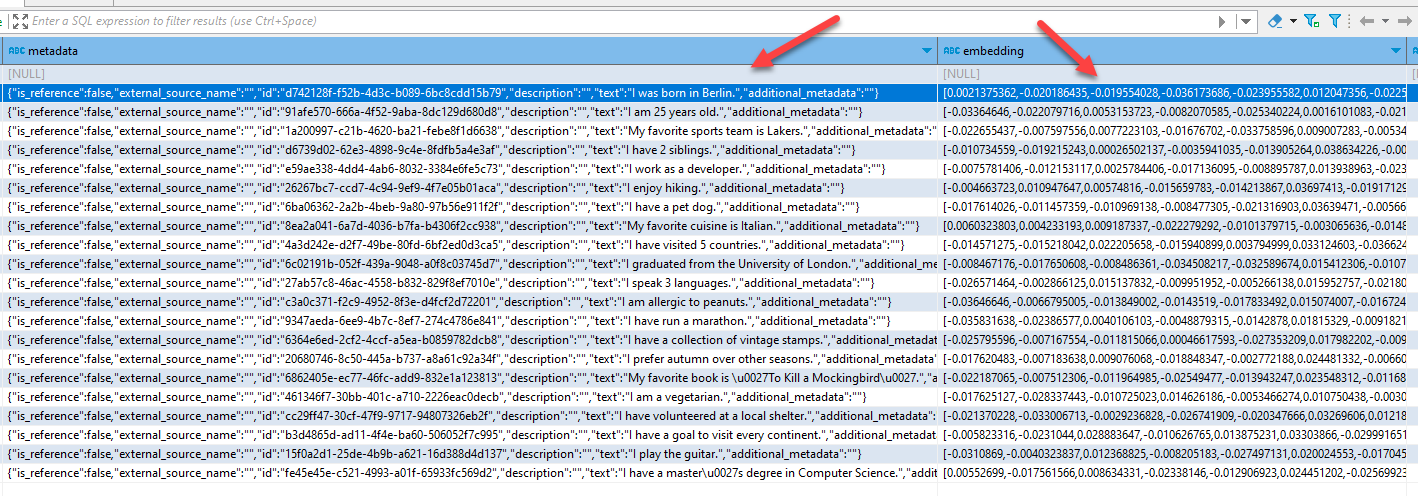
As demonstrated, there are two methods to populate the database. One uses the kernel and a memory-writing function, while the other employs the text memory directly. The final argument in both function calls is a helper class I created to provide sample data. In real-world applications, the input would originate from different sources.
The two methods differ slightly. The first allows for the addition of fields like “description” and “additionalMetadata.” The second utilizes the Kernel and a function but limits data saving to the input field. Perhaps future Semantic Kernel releases will offer more flexibility, or maybe I’ve overlooked some functionality. Either way, the database now contains supplemental data to enhance LLM queries. As previously discussed, LLMs typically rely on their initial parametric memory, but with this added semantic memory, they can expand their knowledge in real-time, leading to improved response quality.
Implementing RAG
There are three methods to utilize this new memory:
- Directly through TextMemory methods
- Using the Kernel with a TextMemory-capable function
- Through the RAG pattern
We’ll explore each method, starting with the most straightforward approach—direct querying of the memory.
This approach directly queries the SemanticTextMemory using the database’s name and our question. The response is a direct replica of the relevant database entry, without any Kernel or LLM involvement. The second method employs the Kernel and the previously imported MemoryPlugin. This approach only has a single query field, “input”, with other parameters set for the collection, answer limits, and relevance threshold.
The third method, using RAG, is the most sophisticated and requires additional configuration:
The RAG method requires several parameters: Memory, Kernel, Collection name, and User Input. Additionally, we need a semantic function to capture user-specific context alongside the LLM query. Hence, we’ve defined an “Assistant” Plugin with a semantic function called “Chat” as seen below:
Its configuration file, config.json, defines two input parameters, user_input and user_context. This ensures that all user inputs capture additional user context, supporting the LLM in responding effectively. As shown in the above ApplyRAG definition, the user_context variable gets populated with memory-retrieved data. This happens transparently with each new question sent to the LLM.
I trust this article has provided clarity on the basics of RAG and its potential applications.
Happy coding with Semantic Kernel!


{kind=link}
{kind=link}
{kind=link}
{kind=link}
One thought on “Intro to Semantic Kernel – Part Four”
THANK YOU for the well written article that considers multiple ways of doing things 🙂 MS should pay you for this supplementary documentation!