
8 minutes read
Sometimes, the hardest part in writing is completing the very first sentence. I began to write the “Loser’s articles” because I wanted to learn a few bits on Data Science, Machine Learning, Spark, Flink etc., but as the time passed by the whole degenerated into a really chaotic mess. This may be a “creative” chaos but still it’s a way too messy to make any sense to me. I’ve got a few positive comments and also a lot of nice tweets, but quality is not a question of comments or individual twitter-frequency. Do these texts properly describe “Data Science”, or at least some parts of it? Maybe they do, but I don’t know for sure.
Whatever, let’s play with Apache Spark’s DataFrames. 😀
The notebook for this article is located here.
Running Apache Spark in Jupyter
Before we start using DataFrames we first have to prepare our environment which will run in Jupyter (formerly known as “IPython”). After you’ve downloaded and unpacked the Spark Package you’ll find some important Python libraries and scripts inside the python/pyspark directory. These files are used, for example, when you start the PySpark REPL in the console. As you may know, Spark supports Java, Scala, Python and R. Python-based REPL called PySpark offers a nice option to control Spark via Python scripts. Just open the console and type in pyspark to start the REPL. If it doesn’t start, please, check your environment variables, especially SPARK_HOME which must point to the root of your Spark installation. Also take care of putting the important sub-directories like python, scala etc. into your PATH variable so the system can find the scripts.
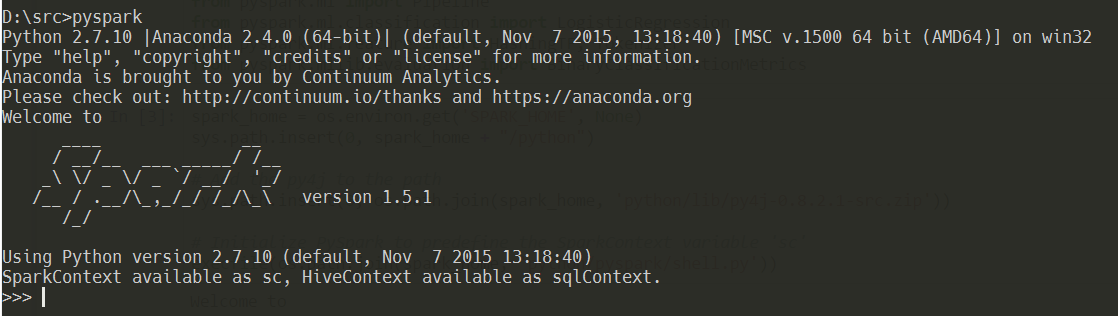
In PySpark you can execute any of the available commands to control your Spark instance, instantiate Jobs, run transformations, actions etc. And the same functionality we want to have inside Jupyter. To achieve this we need to declare a few paths and set some variables inside the Python environment.
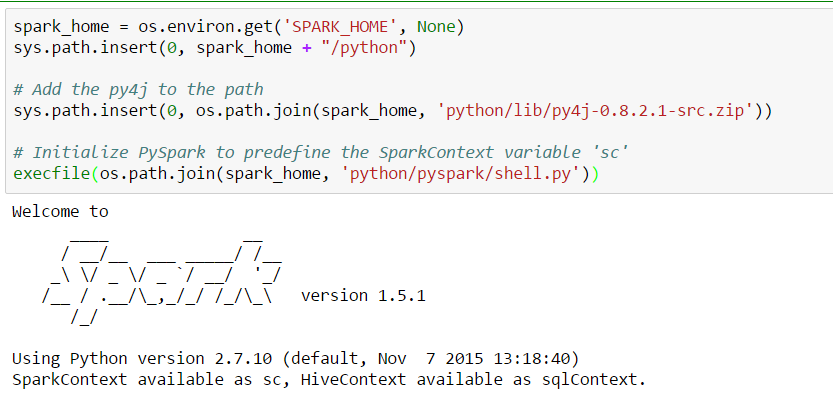
We get the root of our Spark installation, SPARK_HOME, and insert the needed python path. Then, we point to the Py4J package and finally, we execute the shell.py script to initialize a new Spark instance. Ultimately, the Jupyter output returns information about the newly started Spark executor and the two instances: SparkContext and HiveContext. We’ll soon use them to load data and work with DataFrames.
What are DataFrames?
The grandpa of all modern DataFrames like those from pandas or Spark are R’s DataFrames. Basically, they’re 2D-Matrices with a bunch of powerful methods for querying and transforming data. Just imagine you’d have an in-memory representation of a columnar dataset, like a database table or an Excel-Sheet. Everything you can do with such data objects you can do with DataFrames too. You can read a JSON-file, for example, and easily create a new DataFrame based on it. Also, you can save it into a wide variety of formats (JSON, CSV, Excel, Parquet etc.). And for the Spark engine the DataFrames are even more than a transportation format: they define the future API for accessing the Spark engine itself.

As you may already know Spark’s architecture is centered around the term of RDDs (resilient distributed datasets) which are type-agnostic. RDDs don’t know much about the original datatypes of data they distribute over your clusters. Therefore, in situations where you may want to have a typed access to your data you have to deliver your own strategies and this usually involves a lot of boilerplate code. To avoid such scenarios and also to deliver a general, library-independent API the DataFrames will server as the central access point for accessing the underlying Spark libraries (Spark SQL, GraphX, MLlib etc.). Currently, when working on some Spark-based project, it’s not uncommon to have to deal with a whole “zoo” of RDDs which are not compatible: a ScalaRDD is not the same as a PythonRDD, for example. But a DataFrame will always remain just a DataFrame, no matter where it came from and which language you’ve used to create it. Also, the processing of DataFrames is equally fast no matter what language you use. Not so with RDDs. A PythonRDD can never be as fast as ScalaRDDs, for example, because Scala converts directly to ByteCode (and Spark is written in Scala) while PythonRDDs first must be converted into compatible structures before compiling them into ByteCode.
This is how the stadard Spark Data Model built on RDDs looks like:

We take a data set, a log-file, for example, and let Spark create an RDD with several Partitions (physical representations spread over a cluster). Here, each entry is just a line of the whole log-file and we have no direct access to its internal structure. Let’s now check the structure of a DataFrame. In this example we’ll use a JSON-file containing 10.000 Reddit-comments:
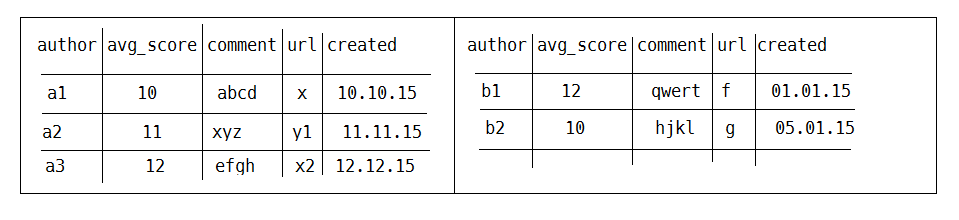
Unlike RDDs DataFrames order data in columnar format and maintain access to their underlying data types. Here we see the original field-names and can access them directly. In the above example only a few of the available fields were shown, so let’s use some real code to load the JSON-file containing the comments and work with it:
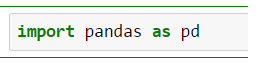
- First, we import the Pandas library for easier accessing of JSON-structures:
- Then we load the original file which is not exactly a JSON-file. Therefore, we have to adjust it a little bit before letting Pandas consume it.
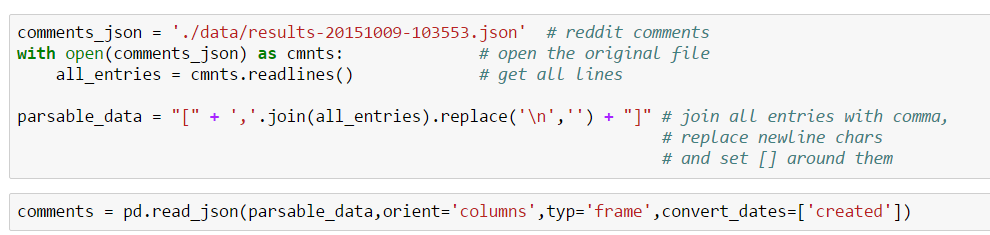
- Now we can use the Pandas DataFrame to create a new Spark DataFrame. From now on we can cache it, check its structure, list columns etc.
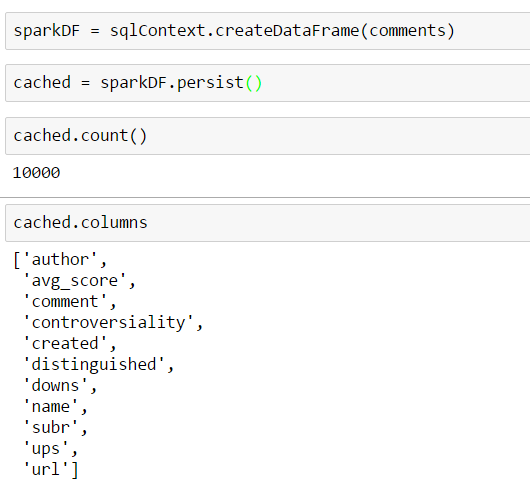
Here we print the underlying schema of our DataFrame:

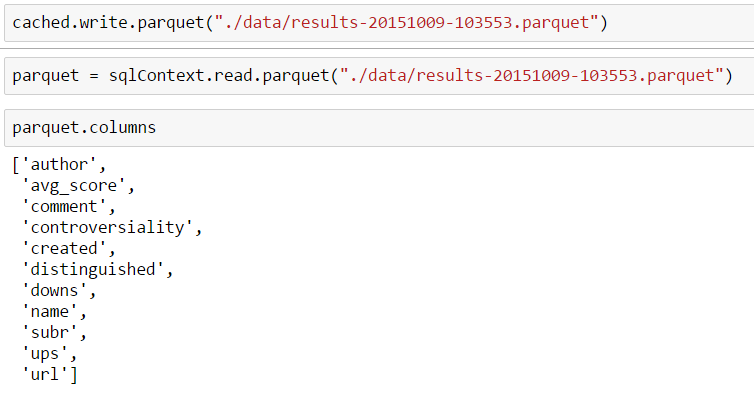
It is important to know that Spark can create DataFrames based on any 2D-Matrix, regardless if its a DataFrame from some other framework, like Pandas, or even a plain structure. For example, we can load a DataFrame from a Parquet.
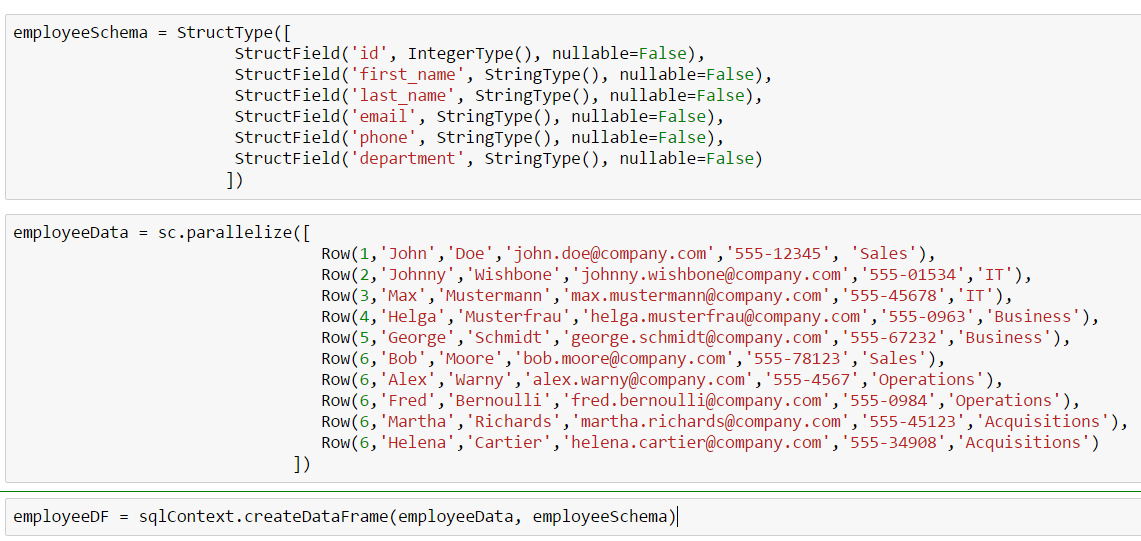
We can manually create DataFrames, too:
And as with RDDs DataFrames are being lazily evaluated. This means that unless you execute any of the available actions (show, collect, count etc.) none of the previously defined transformations (select, filter etc.) will happen.
Querying DataFrames
If you’ve already worked with DataFrames from other frameworks or languages then Spark’s DataFrames will fee very familiar. For example, filtering data can be done with SQL-like commands like:
- select

- first

- selecting multiple columns
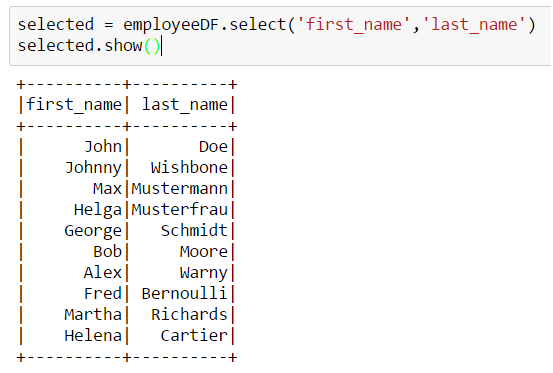
- groupby, filter, join etc.
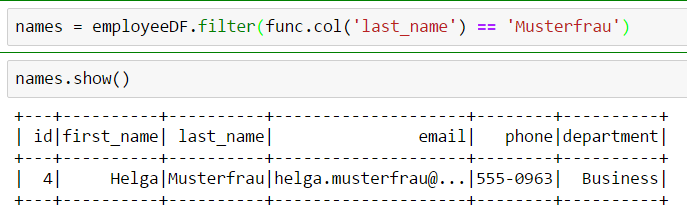
The advantage of this approach is clear: there’s no need to map raw indices to concrete semantics. You just use field names and work on data according to your domain tasks. For example, we can easily create an alias for a certain column:
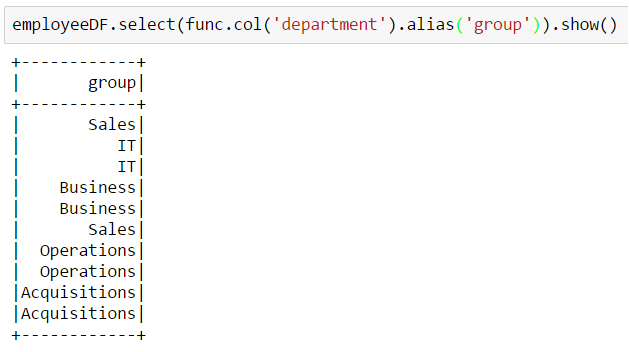
Here we gave the select function a column-object (func.col) which in this case represents the real column “department“. Because we use an object here we also gain access to some additional methods like “alias”. In previous examples the column was represented by a simple string value (the column name) there were not additional methods available.
By using the column object we can also very easily create more complex queries like this grouping/counting example:
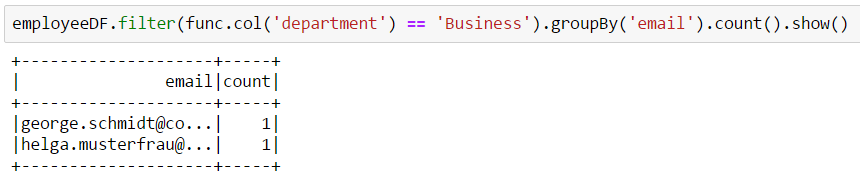
The original namespace where the column-objects reside is pyspark.sql.functions. For our example we created an alias called func. But there’s no need to work only with Spark DataFrames. We can, for example, execute some complex queries which make usage of Spark’s architecture mandatory but the rest of our work still can be done with “standard” tools like Pandas:
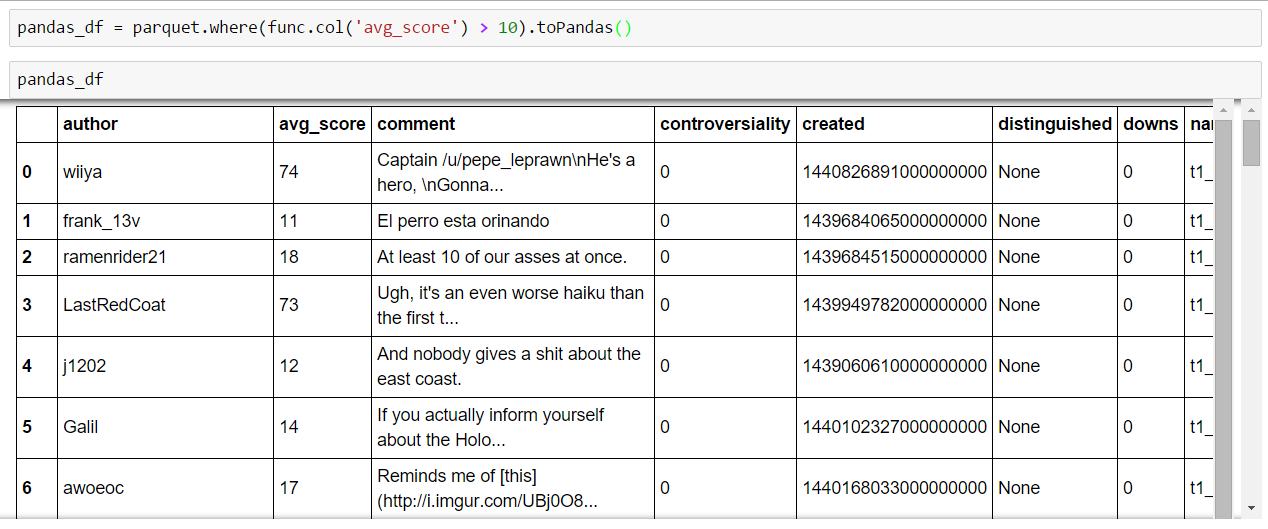
User Defined Functions with DataFrames
As we may already know dealing with data sets involves a lot of scrubbing and massaging data. In our small example with Reddit comments the column “created” contains a TimeStamp value which is semantically not very readable. Pandas users surely know about the different datetime/timestamp conversion functions and in Spark we have a toolset that allows us to define our own functions which operate at the column level: User Defined Functions. Many of you may already have used them with Hive and Pig, so I’ll avoid writing much about the whole theory of UDFs and UDAFs (User Defined Aggregate Functions).
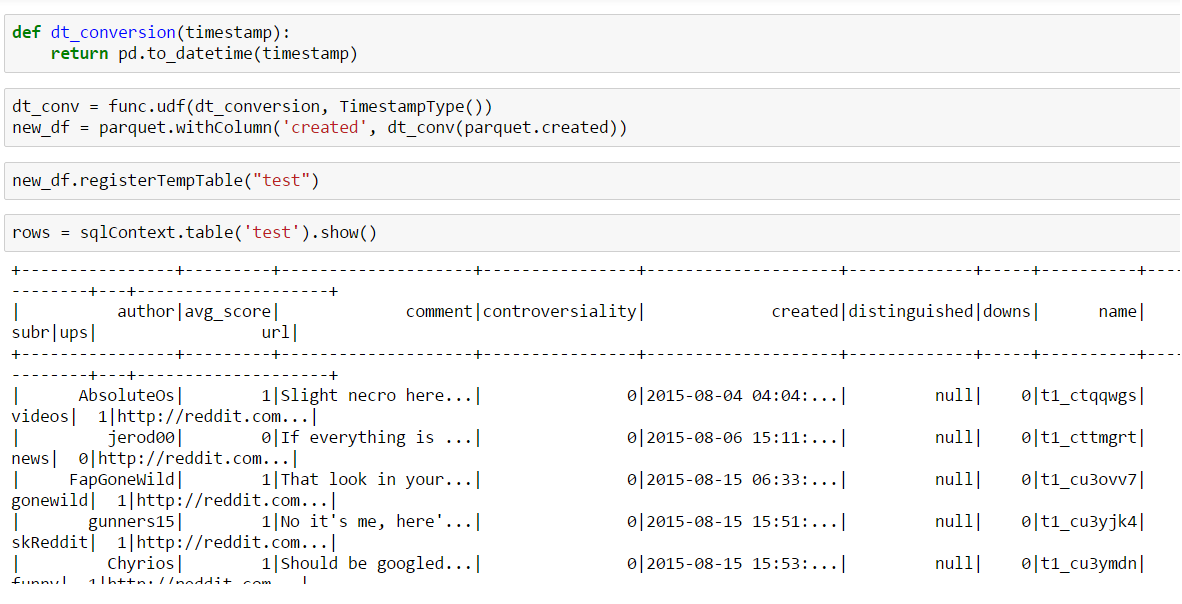
We create a new UDF which takes a single value and its type to convert it to a readable datetime-string by using Pandas’ to_datetime. Then, we let our Spark-DataFrame transform the “created” column by executing withColumn-function which takes our UDF as its second argument.
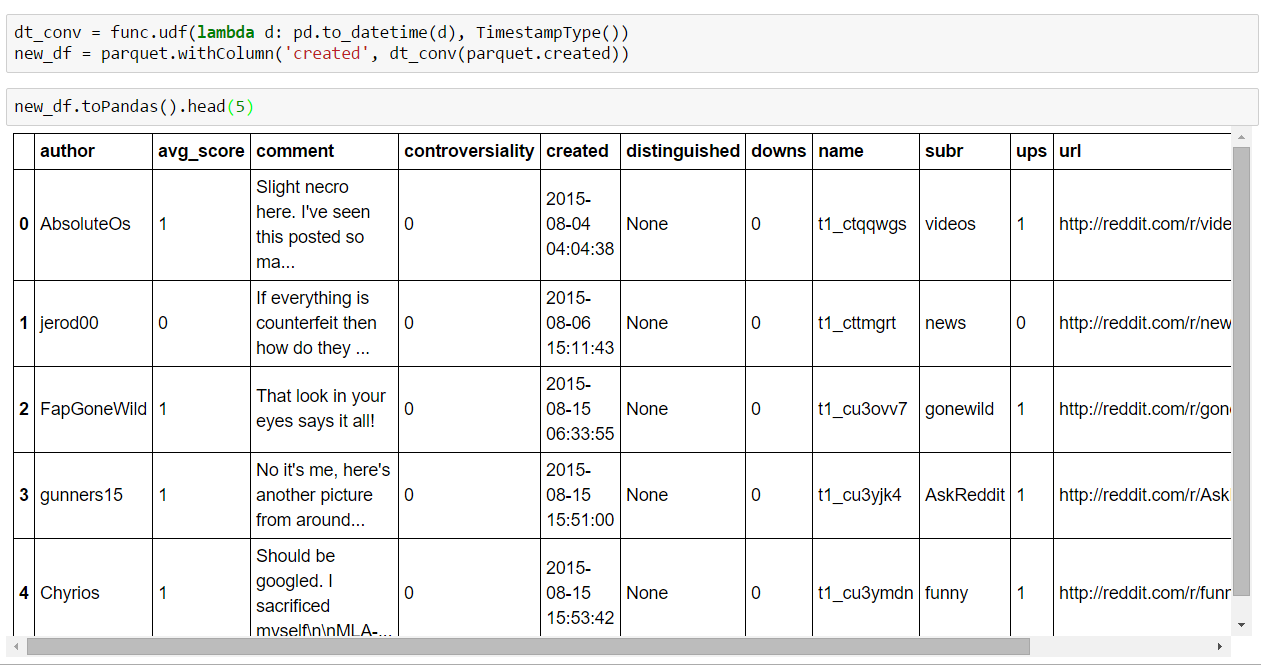
Alternatively, you could also use lambdas and convert results to Pandas’s DataFrames:
It’s also possible to register UDFs so they may be used from another Jupyter notebooks instances, for example.

Conclusion
Working with DataFrames opens a wide range of possibilities not easily available when working with raw RDDs. If you came from Python or R you’ll immediately adopt Spark’s DataFrames. The most important fact is that DataFrames will constitute the central API for working with Spark no matter what language or which library from Spark’s ecosystem you may be using. Everything will ultimately end up as a DataFrame.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
5 thoughts on “Data Science for Losers, Part 5 – Spark DataFrames”
This is an amazing post, thank you really broke down a couple of the stumbling blocks I had with getting my head round not executing SQL and utilizing DataFrames , awesome job!
Your explanation is really good. It cleared a lot of doubts about this topic. Can you please write a post for a regression model with some kind of data manipulation like in pandas in spark.
Very cool. I really liked how you can actually use pd methods and apply them in this distributed fashion.
I think another big advantage is that we can also use SQL syntax in spark environment. It would be cool if you can write another post specifically about this.
Thanks for the blogging and keep it up!
(I use pandas and spark now at Grab, analyzing our traffic data)
Too good. Your acticle lets me understand in depth of dataframes.
Dear all,
Firstly, I would like to thank deeply the author of this blog.
I’ve a request for one of you.
I’ve a problem when executing the code above. It is with the comman line: execfile(os.path ….)). I think it doesn’t work in python 3.5.
Is there any solution?
I tried exec(…). the response of the system was EOL while scanning string literal.
Thank you to everyone who give me a workable solution.
Best regards
M-Larbi.