
13 minutes read
After a long hiatus I’ve decided to revive this blog by writing a series of blog posts related to Bitcoin and it’s architecture. For the most part the articles will discuss certain structures from Bitcoin’s GitHub repository, but I’ll try to explain them without resorting to tech-savvy terms. Some of you might already have invested in Bitcoin or related cryptos but I am pretty sure that most of you have never looked deeper into the architecture than the usual media outlets do. I suppose that you have heard something about the “blockchain” or “distributed ledger”. And of course, there’s no shortage of pundits explaining the (dis)advantages of Bitcoin and how it’ll (destroy?)/(revolutionize?) everything. All in all, the media circus is dutifully delivering the needed injections of (mis)information just like with any other hype. And yes, Bitcoin is a hype, no matter how much one might (dis)like it. A hype is a product of hysteria multiplied by lack of deeper understanding. However, the thing being hyped doesn’t have to be something negative or harmful, just like the Web in the 90es wasn’t something of low value. But the hype surrounding those things can damage the reputation of future products and services. And it usually takes some time to recover financially and regain public trust. This happened with the Web before and I assume it’ll happen with the cryptocurrency market as well.
An individual can’t stop the hype but every individual should accumulate enough knowledge to make him/herself strong enough to withstand the virus of hype. There’s no accumulation of capital without accumulation of knowledge in the first place. It’s no wonder that many follow anonymous “financial experts” on Twitter or Reddit or even pay to join their groups to get “secret knowledge” on how to beat the market. However, I’m not judging anyone of those who follow false prophets. We are free to choose. But, moving in an area without deeper knowledge about the things surrounding you is a recipe for disaster. A very personal disaster. No wonder so many are ready to pay lots of bitcoins to join shady “expert Twitter groups”. The strongest emotion is fear and its strongest variant is the fear of the unknown.
It’s all in the Blocks
There’s no Bitcoin without the Blockchain, just like there’s no Blockchain without its Blocks. We’ll try to understand what a Block is by examining it’s structure from the Bitcoin project itself. Technically savvy readers should use the original C++ source code while I’ll be presenting simplified versions throughout the text. In future articles I’ll be also using other programming languages like Python to describe certain concepts. But for now we’ll stick to the dual C++ representation: simplified C++ here and links to real C++ from the Bitcoin repository.
Basically, every Block contains a BlockHeader and a vector of Transactions.
A vector is just a mathematical way to describe a set of values that belong to a certain category. Just imagine an ordered collection of things that belong to a category called Transactions. Each of those values would have certain features that make them distinguishable from other values belonging to other categories. This is one of the many ways how machines select values.
Regarding Bitcoin a Transaction represents a Transfer of Value from one address to another. And to be accepted as valid a Transaction must find its way into a Block. There are many Transactions trying to reach the Blockchain, but not all of them can be processed at the same time or just a second later. Therefore, Bitcoin participants who create Blocks continuously receive incoming Transactions and some of them land into the next Block while others have to wait for the next Block to be generated.
It depends on different factors like offered transaction fees (the higher the fee you’re willing to pay the faster you’ll get into the next block), available transaction memory pool, the size of the Block itself and so on. Transactions can be of different type which we’ll describe in later articles, but for now, we should simply keep in mind that a Block contains a BlockHeader and a collection of Transactions. Now let’s take a closer look at the BlockHeader.
We see that a BlockHeader is just another class that comprises of several members. And by the way, class is a term used very often by many programming languages to describe things we’re dealing with within a certain domain. Here our domain is Bitcoin and therefore we define our world as something that’s naming things as Blockchain, Blocks, Headers, Transactions, Addresses and so on. We classify those things by giving them meaningful names and assigning them properties. This is why we use classes when we code software. It helps us create and maintain an order to better control our world. Therefore, we have classified this thing called “Blockchain” as a chain of Blocks. And to make it resemble a real chain we define additional things to function as its building blocks (pun intended). However, I don’t want to drain too much of your energy by throwing all this programming stuff at you. But I hope it was sufficient enough to explain some basic coding concepts clearer.
Hashing and Chaining
BlockHeaders carry six members that support core tenets of the Blockchain philosophy. First, BlockHeaders make the chaining of blocks possible. Second, they make sure no one can easily manipulate the blockchain entries, for example by replacing older blocks or changing transactions. Without BlockHeaders the Blockchain couldn’t fulfill it’s most important promise of preventing the double spending problem. Let’s examine the members of BlockHeader class to get a deeper understanding of how hashing and block chaining works.
| Name | Role | Type |
| Version | Version number | numeric |
| PreviousBlockHash | Contains the Block-Hash of the preceding Block | alphanumeric |
| MerkleRootHash | Contains the Root Hash that comprises of all subordinated Transaction Hashes within the current Block | alphanumeric |
| Timestamp | Creation Timestamp in Unix format | numeric |
| TargetToBeSolved | Contains an specifically encoded “target value” that must be used when solving Proof-of-Work problems. For a block to be accepted in the Blockchain the calculated value must be less or equal than “target value”. | encoded byte values |
| NonceForProofOfWork | A numeric value that must be used to generate random data when solving the Proof-of-Work problem for this Block. | numeric |
When a Block comes into existence it’s future place in the Blockchain is determined by the existence of a previous Block that has already found its location on the Blockchain. Just look at the second member of the class BlockHeader: PreviousBlockHash. Previous what? BlockHash what? 😯
To answer these questions one should first take into account that our Blockchain doesn’t deal with accounts, deposits, withdrawals etc. It has no mechanisms available to control such classes of objects. There is no source code for class Account or Deposit in Bitcoin. Such classes belong to centralized mechanisms our today’s banks use to (mis)manage our savings. But how does the Blockchain know which of the Bitcoins belong to me and how much I have to spend or receive, for example?
The answer lies in the fundamental rule that the Blockchain “thinks” in transactions only. Because there’s no central management to maintain the equilibrium of inputs and outputs the only available decentralized mechanism is the control of the transaction flow itself. If you go back and look at the class Block you’ll see that its second member is the collection (vector) of Transactions. Now look at the third member of the class BlockHeader: MerkleRootHash. This variable (yet another term from computing that simply means a thing containing some value) contains the root of a tree-like structure that comprises of all transactions belonging to this Block. Just imagine yourself taking a bunch of transactions and combining their hashes into a simple mathematical tree (displayed upside-down).
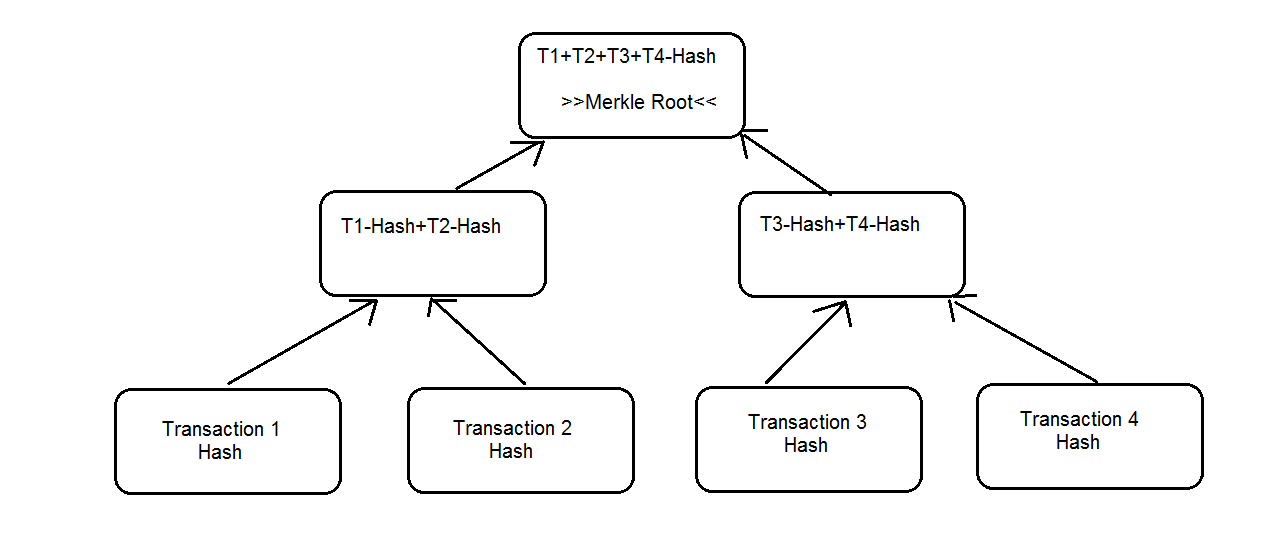
The Merkle Root is a combination of all underlying Transaction-hashes within a Merkle Tree. If you take all transaction hashes from a Block and recursively combine them together you’ll finally end up with a single hash comprising of all preceding hashes. We start at the bottom and generate the first series of hashes. Then we take those from the first level to generate a new series of hashes until we reach a single hash that’ll constitute our root hash. This final hash is called Merkle Root. And it has one interesting quality: if you change any of the underlying transactions the modifications will ripple through the entire tree effectively changing the root itself.
For example, you change some Bitcoin amount within one of the transactions. The immediate outcome would be that not only this single transaction hash would change but also all the combined hashes together up to the Merkle Root itself. No change won’t go unnoticed. Therefore, any manipulation will surely provoke the self-preserving nature of the Blockchain that’ll ultimately result in the rejection of the Block containing these changes. Therefore, a Merkle Tree is not only a very economical way of managing large amounts of data by creating hashes for every transaction, but also a perfect way of taking care that no manipulated blocks could ever reach the Blockchain.
Hash all the Transactions
Before we continue with hashing and chaining of our Block we should quickly define the process of hashing itself. A hash function is a function that can map data of arbitrary size to data of fixed size.
Imagine you want to create fingerprints of all the books from a library to make sure your library’s database contains uniquely identifiable entries. There are all sorts of books with different content, lengths, titles, authors, but you want them to have individual hashes comprising of exactly 32 alphanumeric characters. No more no less. To solve such tasks we use hash functions, because they’re capable of consuming input of any lengths (for example: author info + book content + publication year) while still providing unique values of a fixed length (32 alphanumeric characters for each book).
There are many different hash functions available but we won’t go too deep into them for now. Just take into account that you need some mechanism to uniquely fingerprint certain data so that you can later use those hashes as indicators that the original content remained the same. Therefore, a hash serves as a mechanism to check the integrity of data. If you think that some content has been changed while you weren’t looking at it, just take its original hash and let the current content run through the hash function. If it returns the same hash-result all is fine. If it doesn’t you can be pretty sure that the original data has been changed.
And this is the way Bitcoin clients make sure that no (un)intentionally changed data enters the Blockchain. Each time someone generates a new Block with Transactions in it, all other clients will take this Block-candidate and check the given hashes for validity before allowing it to become part of the Blockchain. Because all clients contain exact copies of the Blockchain it’s very easy to find out if someone is, for example trying to declare that a certain Transaction wants to move “way too much” Bitcoins to some address. 
Imagine now that after we had created a proper Block all other Blockchain participants have accepted it as valid. Our block would now become a part of the Blockchain and the next block in chain would also need a proper HashPrevBlock. Its HashPrevBlock would therefore need the BlockHeader of our own Block to generate this hash.
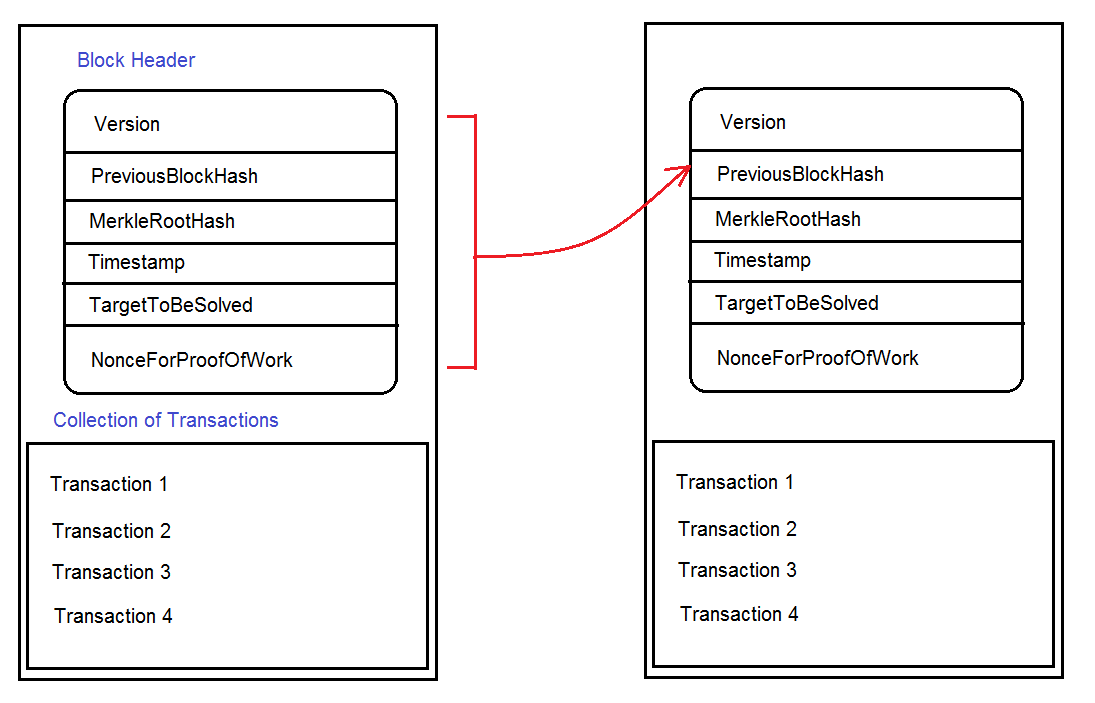
It’s easy to recognize that the role of BlockHeader class is two-fold. First, it serves us as a concept to insert values into variables described in the table above. Second, the BlockHeader as a whole will become an input value of the has-function that generates the next PreviousBlockHash of the Block that follows our own. And by making this possible we let the Blockchain become a proper chain of blocks. By letting each block point to its predecessor we generate a back-linked structure where no single element can be manipulated without affecting all others. A slightest change in some completely unrelated transaction within any of the previous Blocks would provoke a chain reaction that’ll ultimately lead to a Block being rejected by the majority of participants who still follow the unmodified version of the Blockchain.
Here’s a link to a nice visual presentation of this mechanism.
Conclusion
In the world of programming we say: programming is understanding. And I think that the same should apply to the world of finance. These days everything runs on software so it’s not a wonder that even our money will become software. Actually, most of our today’s money has already been software for the most part of its existence. However, we now have erected distributed and decentralized systems capable of creating money and money-like things that refuse to be controlled by anyone. Software systems of that kind can only run autonomously but nevertheless, we, as individuals, should get a more detailed picture of their inner logic. Just like computer literacy is needed to fully participate in pur modern world a certain level of Bitcoin (or if you will “distributed ledger”) literacy will be needed to become an independent participant in the financial systems of the future.
In this article we had barely scratched the surface as I’ve deliberately avoided to show more complex things (“how does a Transaction look like?”) but I promise you that future articles will contain much more code.

{kind=link}
5 thoughts on “Bitcoin Internals, Part 1”
For anyone interested, this is one of the best illustrations of each of the concepts described in this article:
https://anders.com/blockchain/
Hi Michael,
Thanks for the link. I’ll insert it in the article 🙂
Regards,
Hello sir, will you give me permission to use your image depicting a bitcoin blockchain in my internship report? I will link it to this website.
Thank you!
Hi,
Ok, no problem.
This article is great! Thanks for sharing. Really clarified the structure of a block and how transactions get included.