10 minutes read
- Intro to Semantic Kernel – Part One
- Intro to Semantic Kernel – Part Two
- Intro to Semantic Kernel – Part Three
- Intro to Semantic Kernel – Part Four
- Intro to Semantic Kernel – Part Five
- Intro to Semantic Kernel – Addendum
In this article, we will explore Semantic Kernel, an exciting new SDK from Microsoft for interacting with LLMs (Large Language Models) that was open-sourced a few months ago. Lately, tools like ChatGPT have become all the rage. As always, it’ll take a few months for people to grasp what these tools are about and how to handle them properly. Anyone can send text (referred to as “prompts”) to ChatGPT and receive a more or less intelligent response. However, this barely scratches the surface, and unfortunately, many people, tech-savvy folks included, have misinterpreted what LLMs are and how to handle them properly. Sending a prompt to an LLM is akin to feeding a mainframe with punch cards, in my opinion. We are at the onset of a very long journey that will span decades, and just as we cringe at our unearthed Facebook pictures showing us in awkward situations, we might feel the same about our initial attempts at “prompt engineering”. To set the record straight and delve into Semantic Kernel (without further philosophizing): LLMs are the semantic hardware. And nobody with a sane mind communicates with hardware directly, unless you are designing hardware of course. Not sure about you, dear reader, but I assume that people capable of designing such systems won’t be reading my blog 😉
What is Semantic Kernel?
So, what is Semantic Kernel and why do we need it? Semantic Kernel, or SK for short, is an SDK developed by Microsoft that bridges the gap between LLMs, like OpenAI’s ChatGPT, and the various environments we use to develop software that communicates with this “semantic hardware”. SK assists in managing access to LLMs (yes, we can utilize multiple LLMs at once) by providing a well-defined method for creating Plugins (previously referred to as Skills) that encapsulate abilities to be executed by LLMs. The truly exciting part is that SK can also select among available plugins to accomplish a desired task, courtesy of the Planner, a key component of SK. In short, with SK, we can define Plugins that drive the semantic hardware in certain ways, and maintain collections of Plugins that can be automatically selected by SK’s Planner if a task requires multiple steps for successful completion. Unlike interacting with LLMs directly, SK offers a Memory capability, allowing the Planner to retrieve information, from a vector database for instance, and based on that data, distill a Plan of Steps to be executed using certain plugins. This enables us to craft highly flexible, autonomous applications.

SK is highly flexible, offering multiple ways to accomplish similar tasks. One could adopt a more programmatic approach by writing classes and functions representing prompts, plugins, and other instances. Alternatively, a more declarative approach involves writing prompt templates in plain text files and their configurations in JSON files. Despite being written in C#, SK is language-agnostic and can be utilized with Python and Java. The examples further down in this article are partially written in C#, where we configure the Kernel and execute plugin functions. However, the crucial parts are written declaratively, using prompt templates and JSON files. Crafting Plugins for SK may feel a tad unusual initially, as we’re accustomed to programming machines where outcomes are more or less predictable. Traditional computers employ deterministic addressing, fixed memories, constrained persistence mechanisms like SSDs, and operate in a rather “rational” manner. Hence, at the start of every project, the problem isn’t the machine but outside it. It’s our (flawed?) understanding of what needs to be done, how it should be done, and how long it will take to get it done. This isn’t the case with LLMs like ChatGPT, where we lack intimate access to their internals. Apart from knowing the number of tokens they can consume and the size of their outputs, the rest is pretty much a mystery. Questions like how often can I query an LLM in a session before it starts hallucinating, or will this convoluted sentence return factually correct data, or will the LLM fabricate something for the sake of providing an answer, or what does an LLM actually know in the first place, are challenges we face when programming solutions that leverage “artificial intelligence”. One might quip that this new realm of programming involves flawed humans writing buggy programs that run on unreliable semantic hardware. With all this technological progress, it’s sort of getting worse, isn’t it? 😉
First steps
Moving on, let’s commence our journey with SK by crafting more or less realistic applications. In our case, we’ll create two Plugins, DevOps and Engineering, offering Functions that can aid a hypothetical IT company in automating “standard” steps in every DevOps or Engineering project. Imagine, a client requests you to deliver an IDP solution, like setting up a cloud-based identity provider for employee authentication before they can access company resources. This would typically entail orchestrating several containers with Kubernetes, setting up databases, creating realms, connecting external identity providers, and more. The preferred choice for an IDP could be Keycloak, for instance, and to maintain user data, we might deploy PostgreSQL. Of course, there would be scripts to run afterward to meet the unique requirements of our client. Part of our task would be fairly standard, like “deploy Keycloak, deploy DB”, while other aspects would be more specific, like “import DB, import user data, create admin users”, and so on. Looking at these steps, it’s feasible to envision how an AI-powered system could be programmed to execute them automatically. We could create a Plugin named DevOps configured to react to a description of the required tasks by producing a set of YAML files for application via kubectl or, in a more advanced variant, by generating Helm charts for deployment via helm, or even more sophisticated tools like FluxCD, ArgoCD, and the like. The source code of this article contains such a Plugin, encompassing two subfolders representing the Function this Plugin can execute. Within each subdirectory, two files are located: skprompt.txt and config.json. skprompt.txt is where the prompt template or, as Microsoft dubs it, a semantic function is defined.
A semantic function is essentially a prompt sent to an LLM. It can contain not only the text of the prompt but also inline variables defined in the config.json, as demonstrated above with {{$input}}, which represents such a variable.
And the config.json contains the description of the prompt along with the inputs it includes.
The properties “description” appear twice, once for the function description and once for the arguments it expects. It’s crucial to write precise descriptions as they will, for instance, be utilized by the Planner when deciding how to use which functions. Although we won’t delve into the Planner in detail in this article, it’s essential to pen good descriptions anyway. In subsequent articles, we will explore how Planners automatically amalgamate several functions to attain desired outcomes. It’s also worth noting that we could author native functions alongside semantic functions. A native function is essentially a public method of a Plugin class that can be used by SK. But why would we need a native function when we already have our snazzy prompts that can even accept arguments? Well, as most of you have likely realized, LLMs are rather poor at math. They also can’t access the external world. Yes, I know, ChatGPT can browse, but that’s still insufficient. Sometimes, you’d want to access external data in a more controlled manner. Or perform some really complex calculations where you wouldn’t want any LLM to touch any numbers at all. LLMs merely guess computation results anyway. Or how about memorizing and recalling past data? Would you trust an LLM to do that for you? So, there’s a clear need for native functions, but alas, this article won’t cover them. That’s reserved for follow-up articles. Let’s revert to our DevOps Plugin and its Kubernetes Function.
We have now defined the semantic function and organized it as part of our DevOps Plugin. The next step is to test it with our Kernel. In the code below, we instantiate it and inform it about the location of our Plugins. There can be many directories under our root folder, skills, but we don’t need to arrange anything manually. Just let the Kernel collect plugin data automatically.
After compiling the .NET project, we pen a description of the desired Kubernetes deployment for which we’d like SK to generate YAML files. Here is an example file saved as kubernetes_desc.txt.
We will use this file along with the selected Function “Kubernetes” as arguments for our console application. The output will be displayed directly in the console, but I’d recommend redirecting it to a file for further analysis.
dotnet run -- -i ./desc/kubernetes_desc.txt -f Kubernetes > output.txtHere’s how the output appears. It contains the YAML segments of the desired deployment and is formatted exactly as defined in prompt.txt. Every YAML content starts with a FILE: indicator, and their contents are separated with #—-#.
This structure is ideal for automated processing, for example, a shell script. A script capable of generating YAML from these outputs is available under the “scripts” folder in the repository.
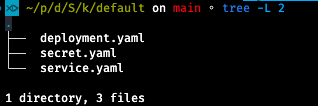
The script can also handle the more complex outputs generated by the Helm Function, which is part of the DevOps Plugin as well. However, I’ll leave that as an exercise for the reader.
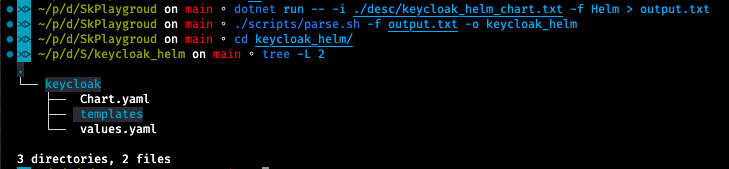
Semantic Kernel is a thrilling piece of software. Although this article only showcased a minuscule number of its capabilities, it’s astonishing how much one can achieve with just a few of its features. Now imagine the possibilities when other instruments come into play, like Planner, Memory, Vector Database support, and so on.
In the upcoming articles, we will explore them all. For now, I hope you’ll start experimenting with Semantic Kernel. It’s undoubtedly worth your time.

{kind=link}
{kind=link}
{kind=link}
{kind=link}