
Sometimes, the hardest part in writing is completing the very first sentence. I began to write the “Loser’s articles” because I wanted to learn a few bits on Data Science, Machine Learning, Spark, Flink etc., but as the time passed by the whole degenerated into a really chaotic mess. This may be a “creative” chaos but still it’s a way too messy to make any sense to me. I’ve got a few positive comments and also a lot of nice tweets, but quality is not a question of comments or individual twitter-frequency. Do these texts properly describe “Data Science”, or at […]
scala
5 posts

It’s been a while since I wrote my last article. A Big-Data Sorry to my “massive” audience. Actually, I was planning to write a follow-up to the last article on Machine Learning but could not find enough time to complete it. Also, I’ll soon give a presentation in a Meetup (in Germany). A classical example on what happens when you have to complete several tasks at the same time. In the end all of them will fail. But I’ll try to compensate it with yet another task: by writing an article about the brand-new Apache Flink v0.10.0 and its DataStream API. 😀 As always, […]

Douglas Crockford once said that people who finally understand Monads immediately lose the capability to explain them to others. Well, the few readers of this chaotic blog are lucky: neither I understand them nor am able to explain them anyway. However, I can say in advance that a Monad in Scala is something that implements two methods: map and flatMap. Haskell coders (luckily, they’re certainly not reading this blog) now would say: No, there’s no flatMap but only bind written as >>=. Yes, I know but anyway, we’ll stick with flatMap. And to make this article somewhat cooler we’ll use a […]
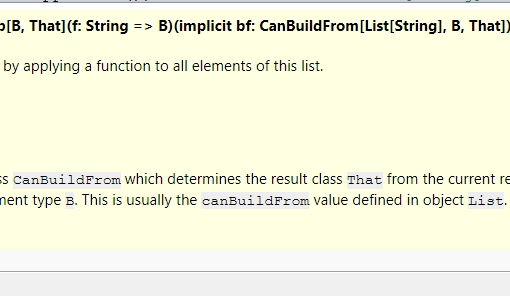
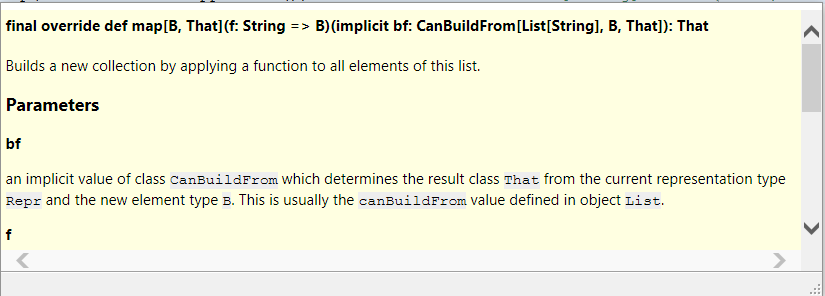
In the last article from the Data Science for Losers series I’ve used a few mini examples in Scala to show how Apache Spark works. Granted, I’m still not sure if this was a “good” idea at all but regarding the fact that the whole series degenerated into something really chaotic a few harmless lines in Scala wouldn’t make it worse anyway. However, the much lower retweet-rate of the last article made it clear that the jump from my bad Python code to my even worse Scala code wasn’t very well accepted. Well, I think it’s time for a crash course in Scala […]
{kind=link}
{kind=link}
{kind=link}
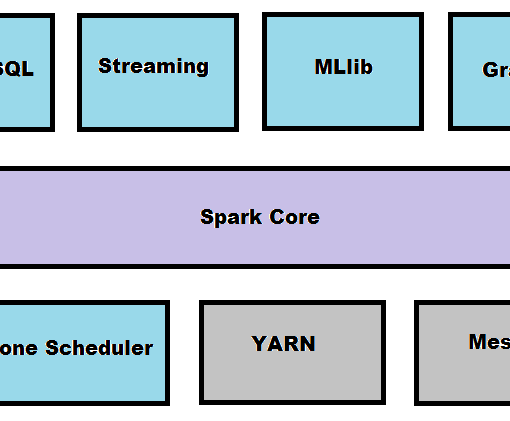
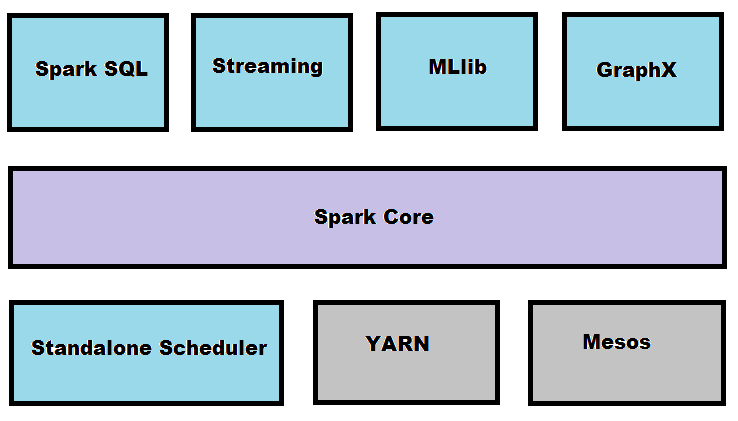
I’ve already mentioned Apache Spark and my irrational plan to integrate it somehow with this series but unfortunately the previous articles were a complete mess so it has had to be postponed. And now, finally, this blog entry is completely dedicated to Apache Spark with examples in Scala and Python. The notebook for this article can be found here. Apache Spark Definition By its own definition Spark is a fast, general engine for large-scale data processing. Well, someone would say: but we already have Hadoop, so why should we use Spark? Such a question I’d answer with a remark that Hadoop is EJB reinvented and […]