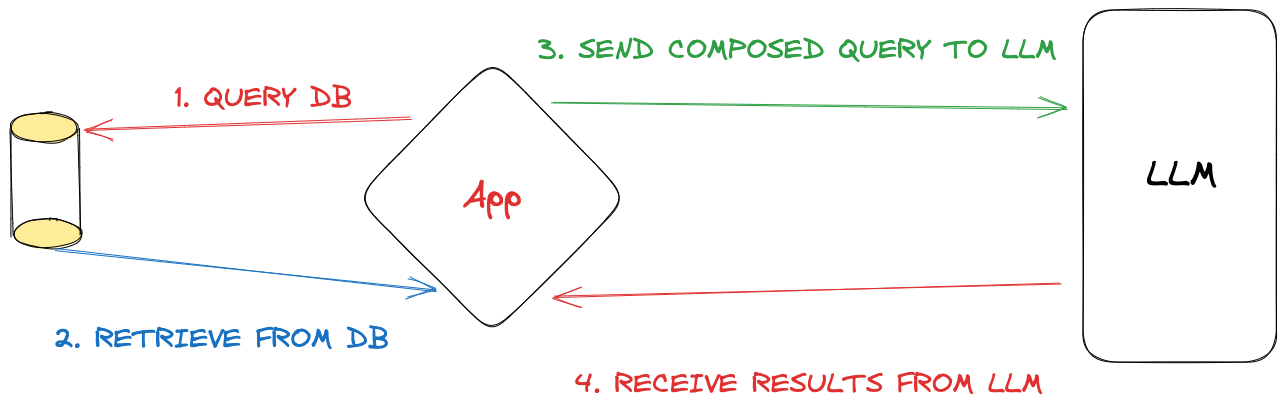
In this post, we explore the fusion of Semantic Kernel with the Retrieval Augmented Generation (RAG) pattern, unraveling a new horizon in AI capabilities. By melding Semantic Kernel’s prowess in understanding relationships between words with RAG’s adeptness in fetching real-world data, we aim to foster models that are not only contextually aware but are also grounded in factual accuracy. Dive in to discover how this amalgamation could be a game-changer in generating more insightful and reliable AI responses.
machinelearning
8 posts
The article elaborates on utilizing Planners with Semantic Kernel to autonomously orchestrate AI tasks based on user requests. It details various Planner types like Basic, Action, Sequential, and Stepwise Planners, explaining their functionalities.

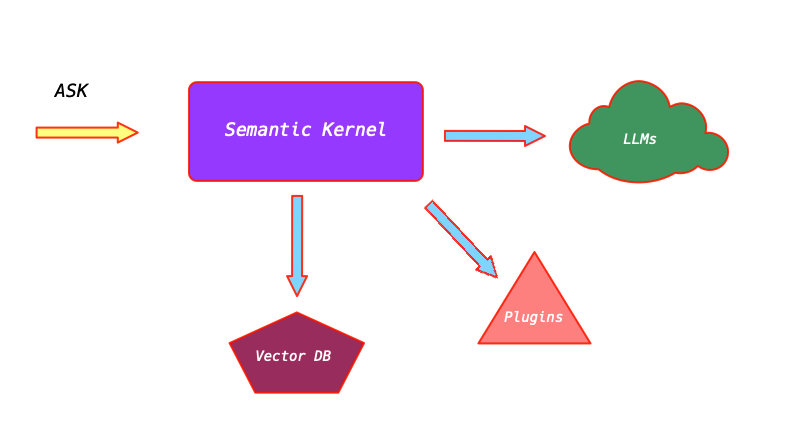
Delve into the world of Semantic Kernel, an innovative SDK by Microsoft, designed to bridge the gap between Large Language Models like OpenAI’s ChatGPT and the diverse software development environments. Explore how Semantic Kernel enhances interaction with LLMs by introducing a structured way to create Plugins and a Planner to manage them. Venture through a practical demonstration of crafting a DevOps Plugin to automate Kubernetes deployment tasks, showcasing the potential of Semantic Kernel in modern software development.
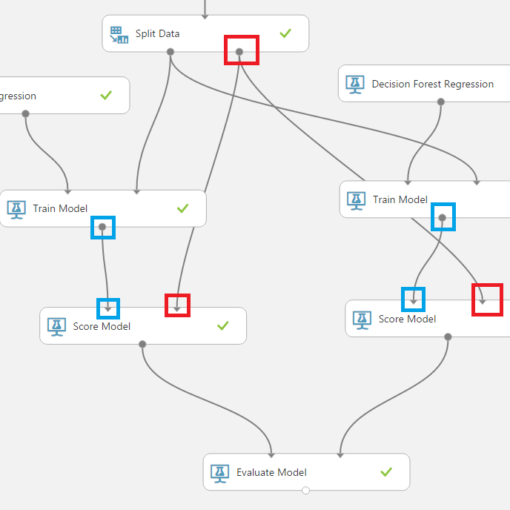
Let me start this article describing the problem I had with finding a proper title for it. As some of you may already know I write a series called “Data Science for Losers” which comprises of several articles that describe different tools, methods and libraries one can use to explore the vast datascientific fields. And just a few days ago, while finishing my Data Science and ML Essentials course, I discovered that Azure ML has a built-in support for Jupyter and Python which, of course, made it very interesting to me because it makes Azure ML an ideal ground for experimentation. […]

In this article we’ll explore Microsoft’s Azure Machine Learning environment and how to combine Cloud technologies with Python and Jupyter. As you may know I’ve been extensively using them throughout this article series so I have a strong opinion on how a Data Science-friendly environment should look like. Of course, there’s nothing against other coding environments or languages, for example R, so your opinion may greatly differ from mine and this is fine. Also AzureML offers a very good R-support! So, feel free to adapt everything from this article to your needs. And before we begin, a few words about how I came […]

Sometimes, the hardest part in writing is completing the very first sentence. I began to write the “Loser’s articles” because I wanted to learn a few bits on Data Science, Machine Learning, Spark, Flink etc., but as the time passed by the whole degenerated into a really chaotic mess. This may be a “creative” chaos but still it’s a way too messy to make any sense to me. I’ve got a few positive comments and also a lot of nice tweets, but quality is not a question of comments or individual twitter-frequency. Do these texts properly describe “Data Science”, or at […]

It’s been a while since I wrote my last article. A Big-Data Sorry to my “massive” audience. Actually, I was planning to write a follow-up to the last article on Machine Learning but could not find enough time to complete it. Also, I’ll soon give a presentation in a Meetup (in Germany). A classical example on what happens when you have to complete several tasks at the same time. In the end all of them will fail. But I’ll try to compensate it with yet another task: by writing an article about the brand-new Apache Flink v0.10.0 and its DataStream API. 😀 As always, […]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
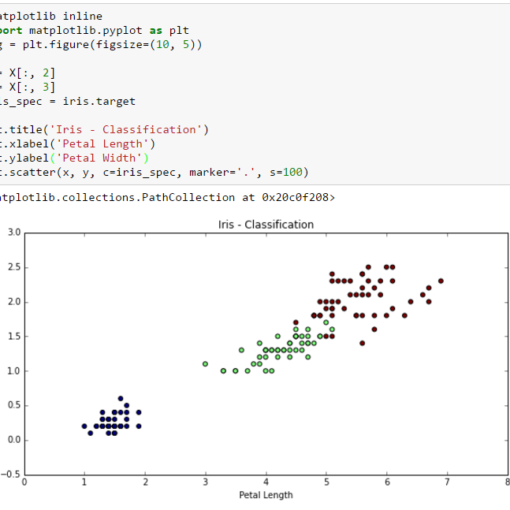
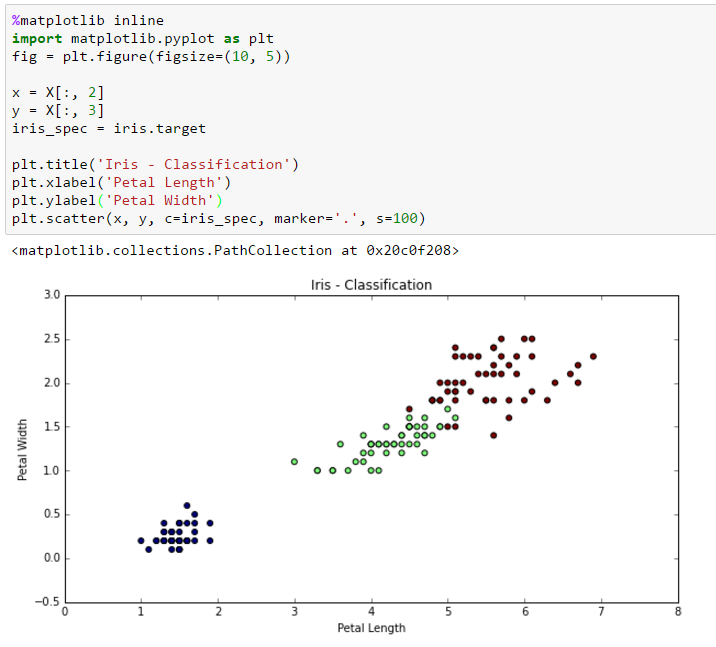
It’s been a while since I’ve written an article on Data Science for Losers. A big Sorry to my readers. But I don’t think that many people are reading this blog. Now let’s continue our journey with the next step: Machine Learning. As always the examples will be written in Python and the Jupyter Notebook can be found here. The ML library I’m using is the well-known scikit-learn. What’s Machine Learning From my non-scientist perspective I’d define ML as a subset of the Artificial Intelligence research which develops self-learning (or self-improving?) algorithms that try to gain knowledge from data and make predictions […]