
In this article we’ll explore Microsoft’s Azure Machine Learning environment and how to combine Cloud technologies with Python and Jupyter. As you may know I’ve been extensively using them throughout this article series so I have a strong opinion on how a Data Science-friendly environment should look like. Of course, there’s nothing against other coding environments or languages, for example R, so your opinion may greatly differ from mine and this is fine. Also AzureML offers a very good R-support! So, feel free to adapt everything from this article to your needs. And before we begin, a few words about how I came […]
jupyter
3 posts
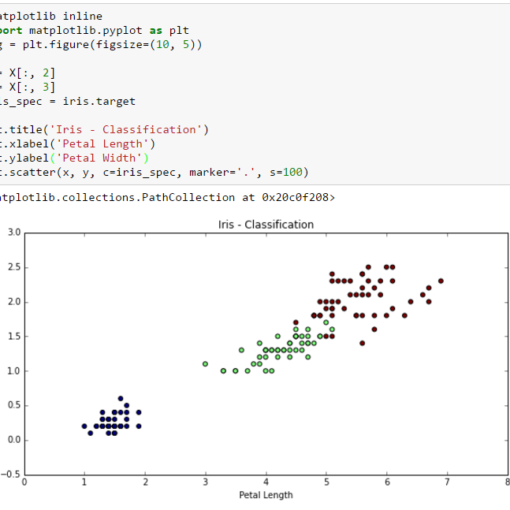
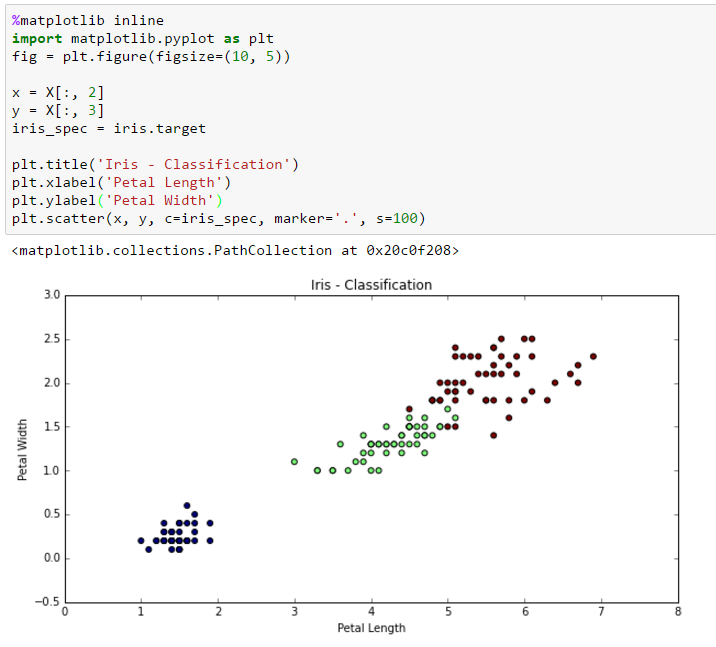
It’s been a while since I’ve written an article on Data Science for Losers. A big Sorry to my readers. But I don’t think that many people are reading this blog. Now let’s continue our journey with the next step: Machine Learning. As always the examples will be written in Python and the Jupyter Notebook can be found here. The ML library I’m using is the well-known scikit-learn. What’s Machine Learning From my non-scientist perspective I’d define ML as a subset of the Artificial Intelligence research which develops self-learning (or self-improving?) algorithms that try to gain knowledge from data and make predictions […]
{kind=link}
{kind=link}
{kind=link}
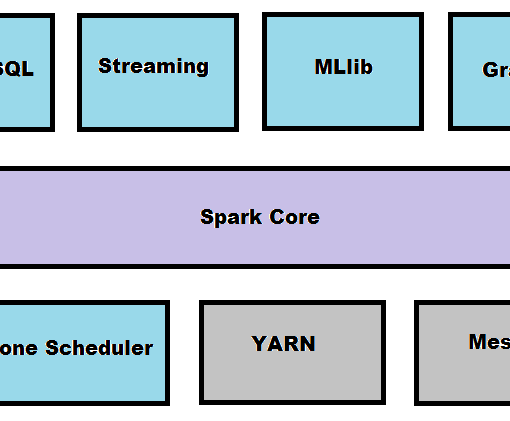
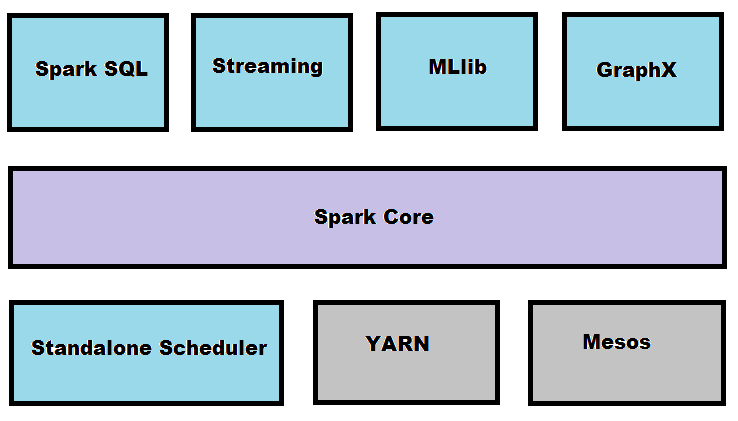
I’ve already mentioned Apache Spark and my irrational plan to integrate it somehow with this series but unfortunately the previous articles were a complete mess so it has had to be postponed. And now, finally, this blog entry is completely dedicated to Apache Spark with examples in Scala and Python. The notebook for this article can be found here. Apache Spark Definition By its own definition Spark is a fast, general engine for large-scale data processing. Well, someone would say: but we already have Hadoop, so why should we use Spark? Such a question I’d answer with a remark that Hadoop is EJB reinvented and […]