
{kind=link}
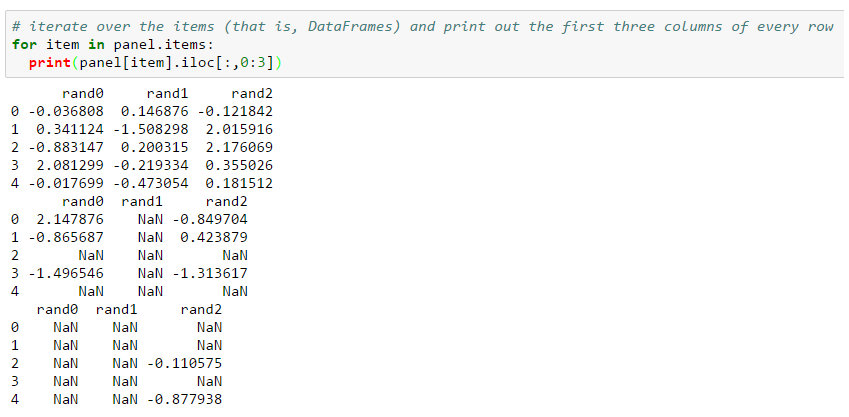
This should have been the third part of the Loser’s article series but as you may know I’m trying very hard to keep the overall quality as low as possible. This, of course, implies missing parts, misleading explanations, irrational examples and an awkward English syntax (it’s actually German syntax covered by English-like semantics 😳 ). And that’s why we now have to go through this addendum and not the real Part Three about using Apache Spark with IPython. The notebook can be found here. So, let’s talk about a few features from Pandas I’ve forgot to mention in the last two articles. Playing SQL with DataFrames Pandas is wonderful because of […]
analysis
1 post